









A dúvida foi:
"Olá Henrique,
sou estudante de computação e na materia de estrutura de dados estamos nessa parte de fila. Tem algumas coisas que eu nao estendi nesse seu código, como por exemplo porque faz: if ( ( (*fim + 1) % TAM ) = = * inicio)
o que tem a ver esse mod(%) pelo tamanho??
Obrigada
Carolina"
Primeiramente obrigado por comentar no blog que visa auxiliar as dúvidas dos internautas.
Respondendo a sua dúvida.
Esse if verifica se a fila está cheia para no caso não inserir elementos na fila.
( ( (*fim + 1) % TAM ) = = * inicio)
Vendo que os ponteiros fim e inicio foram iniciados vazios na fila_vazia:
void fila_vazia (int *i, int *f)
{
*i = 0;
*f = 0;
}
Podemos interpretar o if de outra maneira caso não possua nenhum elemento.
( ( (0 + 1) % 10 ) = = 0)
Em que o resto da divisão de 1 por 10 é 1 diz que essa condição é falsa.
Agora o porque de usar o mod(%) pelo tamanho?
Isso é usado para ver se o parâmetro *fim está com a quantidade máxima de elementos que ela pode receber.
Como o TAM é 10 e a cada nova inserção é adicionado ao ponteiro *fim um valor além do que foi inserido anteriormente na condição else (*fim = (* fim + 1) % TAM;).
Se for inserido 10 elementos na fila a condição if passa a ser:
( ( (9 + 1) % 10 ) = = 0)
O resto da divisão de 10 por 10 é zero que é igual ao ponteiro de início.
Espero ter respondido a sua dúvida e continue a comentar no blog.
Muito Obrigado Carolina fique com Deus.
segunda-feira, 14 de junho de 2010
quarta-feira, 19 de maio de 2010
Referências
Segue aqui as referências para o desenvolvimento desse tutorial.
VELOSO, Paulo et al. Estrutura de dados. Rio de Janeiro: Campus, 1983.
PEREIRA, Silvio do Lago. Estruturas de dados fundamentais. São Paulo: Érica, 2009.
TENENBAUM, Aaron M.; LANGSAM, Yedidyah; AUGENSTEIN, Moshe J.; Estruturas de dados usando C. São Paulo: Makron Books, 1995.
DUARTE, Kátia; Tutorial Linguagem C – Matrizes. S.L 2005. Disponível em: http://www.juliobattisti.com.br/tutoriais/katiaduarte/cbasico004.asp
PINHO, Márcio Sarroglia; Material de consulta de Linguagem C. Porto Alegre PUCRS, S.D. Disponível em: http://www.inf.pucrs.br/~pinho/LaproI/Vetores/Vetores.htm#ExemplosVet
MANSSOUR, Isabel Harb; Linguagem de Programação C. Porto Alegre PUCRS, 2001. Disponível em: http://www.inf.pucrs.br/~manssour/LinguagemC
SCHILDT, Herbert apud MANSSOUR, Isabel Harb. C Completo e total. São Paulo: Makron Books, 1996.
SOULIE, Juan; C++ Language Tutorial. S.L, 2009. Disponível em: http://www.cplusplus.com/doc/tutorial/
TESSLER, Eduardo; O que é e pra que serve a Internet? S. L 2009. Disponível em: http://www.midiamundo.com/2009/09/o-que-e-e-para-que-serve-internet.html
MOTA, Kleber; Estruturas de dados – conceitos básicos. S.L, 2009. Disponível em: http://www.klebermota.eti.br/2009/08/estrutura-de-dados-conceitos-basicos/
SUAVÉ, Jacques Philippe; Estruturas de dados – tipos de coleções. Campina Grande UFCG, 2007. Disponível em: http://www.dsc.ufcg.edu.br/~jacques/cursos/p2/html/ed/colecoes.htm
FEOFILOFF, Paulo; Linguagem C: struct. São Paulo USP, 2008. Disónível em: http://www.ime.usp.br/~pf/algoritmos/aulas/stru.html
DUARTE, Kátia; Tutorial Linguagem C – Alocação Dinâmica. S.L 2006. Disponível em: http://www.juliobattisti.com.br/tutoriais/katiaduarte/cbasico009.asp
VELOSO, Paulo et al. Estrutura de dados. Rio de Janeiro: Campus, 1983.
PEREIRA, Silvio do Lago. Estruturas de dados fundamentais. São Paulo: Érica, 2009.
TENENBAUM, Aaron M.; LANGSAM, Yedidyah; AUGENSTEIN, Moshe J.; Estruturas de dados usando C. São Paulo: Makron Books, 1995.
DUARTE, Kátia; Tutorial Linguagem C – Matrizes. S.L 2005. Disponível em: http://www.juliobattisti.com.br/tutoriais/katiaduarte/cbasico004.asp
PINHO, Márcio Sarroglia; Material de consulta de Linguagem C. Porto Alegre PUCRS, S.D. Disponível em: http://www.inf.pucrs.br/~pinho/LaproI/Vetores/Vetores.htm#ExemplosVet
MANSSOUR, Isabel Harb; Linguagem de Programação C. Porto Alegre PUCRS, 2001. Disponível em: http://www.inf.pucrs.br/~manssour/LinguagemC
SCHILDT, Herbert apud MANSSOUR, Isabel Harb. C Completo e total. São Paulo: Makron Books, 1996.
SOULIE, Juan; C++ Language Tutorial. S.L, 2009. Disponível em: http://www.cplusplus.com/doc/tutorial/
TESSLER, Eduardo; O que é e pra que serve a Internet? S. L 2009. Disponível em: http://www.midiamundo.com/2009/09/o-que-e-e-para-que-serve-internet.html
MOTA, Kleber; Estruturas de dados – conceitos básicos. S.L, 2009. Disponível em: http://www.klebermota.eti.br/2009/08/estrutura-de-dados-conceitos-basicos/
SUAVÉ, Jacques Philippe; Estruturas de dados – tipos de coleções. Campina Grande UFCG, 2007. Disponível em: http://www.dsc.ufcg.edu.br/~jacques/cursos/p2/html/ed/colecoes.htm
FEOFILOFF, Paulo; Linguagem C: struct. São Paulo USP, 2008. Disónível em: http://www.ime.usp.br/~pf/algoritmos/aulas/stru.html
DUARTE, Kátia; Tutorial Linguagem C – Alocação Dinâmica. S.L 2006. Disponível em: http://www.juliobattisti.com.br/tutoriais/katiaduarte/cbasico009.asp
terça-feira, 18 de maio de 2010
Filas
A fila é um dos métodos em estruturas de dados em que possui conceitos de inserir e remover dados junto com o conceito de pilhas e listas porém a fila é independente desses métodos de implementação devido ao seu funcionamento.

A organização das filas se iguala as filas convencionais que estão presentes no cotidiano visto que a fila funciona na ordem de que o as pessoas entram no fim da fila e as pessoas saem no começo da fila. (PEREIRA, 2009).
As filas funcionam em esquema de FIFO (First In – First Out), ou seja, primeiro que entra e o último que sai visto na figura a seguir. (PEREIRA, 2009).

Tenenbaum; Langsam; Augenstein; (1995, p.207) afirma que uma fila é um conjunto ordenado de itens a partir do qual pode-se eliminar itens numa extremidade (chamada início da fila) e no qual pode-se inserir itens na outra extremidade (chamada final da fila).
As filas utilizam uma estrutura similar ao conceito de pilhas porem possui um novo parâmetro auxiliar que indica o fim da fila.
#define TAM 10
typedef struct
{
int inicio[TAM];
int fim;
}; fila;
As filas são similares a uma lista circular, em que a variável auxiliar “inicio” encontra-se na mesma posição da variável “fim” ao iniciar a fila.
void fila_vazia (int *i, int *f)
{
*i = 0;
*f = 0;
}
A fila inicia vazia recebendo os parâmetros auxiliares de sua estrutura “inicio” e “fim”, esses dois parâmetros recebem valor “0” de modo que esses parâmetros auxiliarem inicia-se juntos pertencentes à fila.
Para realizar a inclusão ou a remoção de informação da fila é necessário que as variáveis auxiliares sejam bem definidas para que a fila funcione corretamente.
int ins_fila (int *fila, int *inicio, int *fim, int val)
{
if ( ( (*fim + 1) % TAM ) = = * inicio)
return 0;
else
{
*fim = (* fim + 1) % TAM;
fila [* fim ] = Val;
return 1;
}
}
O método de inserir elementos recebe como parâmetros a estrutura da fila, as variáveis “inicio” e “fim” para manipular a informação e recebe a informação que será inserida. Para realizar a inclusão é verificado se a fila já esta cheia, se a variável “fim“ obtiver o mesmo tamanho que a variável “inicio” quer dizer que a fila está cheia e a operação não é concluída, agora no caso das variáveis não serem iguais nos seus valores a variável “fim” recebe um acréscimo no seu valor e em seguida a fila na posição da variável “fim” recebe a informação e o método conclui com sucesso.
Int rem_fila (int * fila, int *inicio, int *fim, int *val)
{
If ( *fim = = * inicio)
return 0;
else
{
*inicio = (* inicio + 1 ) % TAM;
*val = fila[* inicio];
return 1;
}
}
O método de remover as informações da fila possui um método de verificar diferenciado do método de incluir, pois a inclusão verifica se a lista está cheia analisando se os seus valores estão iguais ao valor definido “TAM” e o método de remover verifica se os dois valores são iguais sendo que são “0” ou seja, a fila não possui nenhuma informação e a operação de remoção não é concluída, caso a fila possua algum elemento o ponteiro inicio recebe um acréscimo no seu valor e depois o valor é removido da fila.

A organização das filas se iguala as filas convencionais que estão presentes no cotidiano visto que a fila funciona na ordem de que o as pessoas entram no fim da fila e as pessoas saem no começo da fila. (PEREIRA, 2009).
As filas funcionam em esquema de FIFO (First In – First Out), ou seja, primeiro que entra e o último que sai visto na figura a seguir. (PEREIRA, 2009).

Tenenbaum; Langsam; Augenstein; (1995, p.207) afirma que uma fila é um conjunto ordenado de itens a partir do qual pode-se eliminar itens numa extremidade (chamada início da fila) e no qual pode-se inserir itens na outra extremidade (chamada final da fila).
As filas utilizam uma estrutura similar ao conceito de pilhas porem possui um novo parâmetro auxiliar que indica o fim da fila.
#define TAM 10
typedef struct
{
int inicio[TAM];
int fim;
}; fila;
As filas são similares a uma lista circular, em que a variável auxiliar “inicio” encontra-se na mesma posição da variável “fim” ao iniciar a fila.
void fila_vazia (int *i, int *f)
{
*i = 0;
*f = 0;
}
A fila inicia vazia recebendo os parâmetros auxiliares de sua estrutura “inicio” e “fim”, esses dois parâmetros recebem valor “0” de modo que esses parâmetros auxiliarem inicia-se juntos pertencentes à fila.
Para realizar a inclusão ou a remoção de informação da fila é necessário que as variáveis auxiliares sejam bem definidas para que a fila funcione corretamente.
int ins_fila (int *fila, int *inicio, int *fim, int val)
{
if ( ( (*fim + 1) % TAM ) = = * inicio)
return 0;
else
{
*fim = (* fim + 1) % TAM;
fila [* fim ] = Val;
return 1;
}
}
O método de inserir elementos recebe como parâmetros a estrutura da fila, as variáveis “inicio” e “fim” para manipular a informação e recebe a informação que será inserida. Para realizar a inclusão é verificado se a fila já esta cheia, se a variável “fim“ obtiver o mesmo tamanho que a variável “inicio” quer dizer que a fila está cheia e a operação não é concluída, agora no caso das variáveis não serem iguais nos seus valores a variável “fim” recebe um acréscimo no seu valor e em seguida a fila na posição da variável “fim” recebe a informação e o método conclui com sucesso.
Int rem_fila (int * fila, int *inicio, int *fim, int *val)
{
If ( *fim = = * inicio)
return 0;
else
{
*inicio = (* inicio + 1 ) % TAM;
*val = fila[* inicio];
return 1;
}
}
O método de remover as informações da fila possui um método de verificar diferenciado do método de incluir, pois a inclusão verifica se a lista está cheia analisando se os seus valores estão iguais ao valor definido “TAM” e o método de remover verifica se os dois valores são iguais sendo que são “0” ou seja, a fila não possui nenhuma informação e a operação de remoção não é concluída, caso a fila possua algum elemento o ponteiro inicio recebe um acréscimo no seu valor e depois o valor é removido da fila.
Pilhas
As pilhas são implementações parecidas com as listas em que a pilha possui uma maior organização de suas informações e também conceitos que facilitam o entendimento do programador.
Tenenbaum; Langsam; Augenstein; (1995, p.86) argumentam que uma pilha é conjunto ordenado de itens em que novos itens podem ser inseridos e a partir do qual podem ser eliminados itens em uma extremidade chamada de topo da pilha. Ao contrário do que acontece com o vetor, a definição da pilha compreende a inserção e a eliminação de itens, de modo que uma é um objeto dinâmico, constantemente mutável.

A implementação de pilha coloca novos elementos no seu topo e apenas a informação do topo da lista pode ser removido, a pilha utiliza a política de acesso LIFO (Last-In First Out) significa que o último elemento inserido deve ser o primeiro a ser removido. (PEREIRA, 2009).

A pilha possui a vantagem de poder limitar a quantidade de elementos que estão contidos, com isso ela é similar a um vetor de tamanho definido e também a uma lista encadeada. Há várias vantagens no método de pilha em que é possível criar históricos de páginas visitadas e também comando de desfazer em editores de texto.
O método de criar uma pilha é similar ao conceito de lista em que utiliza o conceito de “struct” ou um registro para iniciar a pilha.
#define TAM 10
typedef struct
{
int topo;
int el[TAM];
}; pilha
A estrutura da pilha funciona com o seu topo que é o primeiro elemento da pilha e indica a posição que a informação está e em seguida o vetor “el” recebe as informações e somente obterá novas informações até chegar ao valor definido em “TAM”.
Como visto a pilha tem o topo como primeiro elemento, com isso a pilha é iniciada a partir do topo igual a -1 pois o vetor tem seu elemento 0 como primeiro valor válido.
void inicia (pilha *p)
{
p-> topo = -1;
}
A pilha é iniciada tendo como parâmetro o ponteiro “p” em que auxiliará na organização de entrada de novas informações na pilha. O topo é iniciado na posição “-1” é necessário que o programador entenda que não é atribuído valores ou informações aos ponteiros, mas sim ao endereço em que o topo se encontra, esse valor de endereço “-1” é utilizado para que seja possível equalizar os valores de tamanho da pilha.
Para implementações nas pilhas como inserir ou retirar valores é necessário para o desenvolvimento dos algoritmos ou programas verifiquem se a pilha está cheia ou vazia, pois a pilha possui um tamanho limite de informações que ela pode receber e para o caso de estar vazia e se estiver cheia o comando de inserir não acontecerá.
int cheia (pilha *p)
{
return (p->topo = = TAM –1);
}
Esse método verificará se a pilha está cheia, para isso o é utilizado o método do tipo int no qual é possível retornar informações através do comando “return” no caso da condição que o comando “return” possui seja verdadeiro a condição que o método “cheia” esteja não será possível inserir novos valores na pilha.
int vazia (pilha *p)
{
Return (p->topo = = -1);
}
O método descrito verifica se a pilha está vazia, em que a condição dentro do comando “return” for verdadeira quer dizer que a pilha está realmente vazia pois o “p->topo” iniciou com o valor “-1” justamente para ter a possibilidade de verificar se existe elementos na lista e poder acrescentar até o limite de elementos “TAM”.
Os métodos de inserir e remover valores na pilha são demonstrados como “push” e “pop” em que o comando “push” acrescentará novas informações e “pop” removerá as informações.
Com isso foi necessário os métodos de verificar se a lista está cheia ou vazia para possibilitar o funcionamento dos comandos “push” e “pop”.
int push (pilha *p, int val)
{
if ( cheia ( p ) )
return 0;
p->el[+ + p->topo] = val;
return 1;
}
O comando “push” insere um novo valor na pilha, em que ele pega o parâmetro da pilha e da informação a que será inserida após isso o comando verifica se a pilha está cheia através do método “cheia” que foi argumentado, caso a pilha esteja sem espaço para novos elementos ela retornará “0” no qual diz que a pilha está completa, caso a condição seja falsa a variável que determina a quantidade de elementos da pilha “el” receberá a nova informação no topo da pilha e retornará “1” em que confirma a operação na pilha.
int pop (pilha *p, int *val)
{
if ( vazia ( p ) )
return 0;
*val = p->el [p->topo - - ];
return 1;
}
Esse método “pop” remove as informações contidas na pilha, de modo o valor agora é preciso ser passado como parâmetro para possibilitar a remoção da informação. É preciso que o comando de remoção verifique se a pilha está vazia para realizar a sua operação, se a pilha estiver vazia o método não remove a informação e se a pilha contiver elementos o comando remove o elemento da pilha em que a informação removida é a primeira da lista.
A pilha pode ser manipulada pelos comandos “push” e “pop” que realizam grande funcionalidade para a pilha. Em suma a pilha é um método de inserção e remoção de dados mais apurada que as listas.
Tenenbaum; Langsam; Augenstein; (1995, p.86) argumentam que uma pilha é conjunto ordenado de itens em que novos itens podem ser inseridos e a partir do qual podem ser eliminados itens em uma extremidade chamada de topo da pilha. Ao contrário do que acontece com o vetor, a definição da pilha compreende a inserção e a eliminação de itens, de modo que uma é um objeto dinâmico, constantemente mutável.

A implementação de pilha coloca novos elementos no seu topo e apenas a informação do topo da lista pode ser removido, a pilha utiliza a política de acesso LIFO (Last-In First Out) significa que o último elemento inserido deve ser o primeiro a ser removido. (PEREIRA, 2009).

A pilha possui a vantagem de poder limitar a quantidade de elementos que estão contidos, com isso ela é similar a um vetor de tamanho definido e também a uma lista encadeada. Há várias vantagens no método de pilha em que é possível criar históricos de páginas visitadas e também comando de desfazer em editores de texto.
O método de criar uma pilha é similar ao conceito de lista em que utiliza o conceito de “struct” ou um registro para iniciar a pilha.
#define TAM 10
typedef struct
{
int topo;
int el[TAM];
}; pilha
A estrutura da pilha funciona com o seu topo que é o primeiro elemento da pilha e indica a posição que a informação está e em seguida o vetor “el” recebe as informações e somente obterá novas informações até chegar ao valor definido em “TAM”.
Como visto a pilha tem o topo como primeiro elemento, com isso a pilha é iniciada a partir do topo igual a -1 pois o vetor tem seu elemento 0 como primeiro valor válido.
void inicia (pilha *p)
{
p-> topo = -1;
}
A pilha é iniciada tendo como parâmetro o ponteiro “p” em que auxiliará na organização de entrada de novas informações na pilha. O topo é iniciado na posição “-1” é necessário que o programador entenda que não é atribuído valores ou informações aos ponteiros, mas sim ao endereço em que o topo se encontra, esse valor de endereço “-1” é utilizado para que seja possível equalizar os valores de tamanho da pilha.
Para implementações nas pilhas como inserir ou retirar valores é necessário para o desenvolvimento dos algoritmos ou programas verifiquem se a pilha está cheia ou vazia, pois a pilha possui um tamanho limite de informações que ela pode receber e para o caso de estar vazia e se estiver cheia o comando de inserir não acontecerá.
int cheia (pilha *p)
{
return (p->topo = = TAM –1);
}
Esse método verificará se a pilha está cheia, para isso o é utilizado o método do tipo int no qual é possível retornar informações através do comando “return” no caso da condição que o comando “return” possui seja verdadeiro a condição que o método “cheia” esteja não será possível inserir novos valores na pilha.
int vazia (pilha *p)
{
Return (p->topo = = -1);
}
O método descrito verifica se a pilha está vazia, em que a condição dentro do comando “return” for verdadeira quer dizer que a pilha está realmente vazia pois o “p->topo” iniciou com o valor “-1” justamente para ter a possibilidade de verificar se existe elementos na lista e poder acrescentar até o limite de elementos “TAM”.
Os métodos de inserir e remover valores na pilha são demonstrados como “push” e “pop” em que o comando “push” acrescentará novas informações e “pop” removerá as informações.
Com isso foi necessário os métodos de verificar se a lista está cheia ou vazia para possibilitar o funcionamento dos comandos “push” e “pop”.
int push (pilha *p, int val)
{
if ( cheia ( p ) )
return 0;
p->el[+ + p->topo] = val;
return 1;
}
O comando “push” insere um novo valor na pilha, em que ele pega o parâmetro da pilha e da informação a que será inserida após isso o comando verifica se a pilha está cheia através do método “cheia” que foi argumentado, caso a pilha esteja sem espaço para novos elementos ela retornará “0” no qual diz que a pilha está completa, caso a condição seja falsa a variável que determina a quantidade de elementos da pilha “el” receberá a nova informação no topo da pilha e retornará “1” em que confirma a operação na pilha.
int pop (pilha *p, int *val)
{
if ( vazia ( p ) )
return 0;
*val = p->el [p->topo - - ];
return 1;
}
Esse método “pop” remove as informações contidas na pilha, de modo o valor agora é preciso ser passado como parâmetro para possibilitar a remoção da informação. É preciso que o comando de remoção verifique se a pilha está vazia para realizar a sua operação, se a pilha estiver vazia o método não remove a informação e se a pilha contiver elementos o comando remove o elemento da pilha em que a informação removida é a primeira da lista.
A pilha pode ser manipulada pelos comandos “push” e “pop” que realizam grande funcionalidade para a pilha. Em suma a pilha é um método de inserção e remoção de dados mais apurada que as listas.
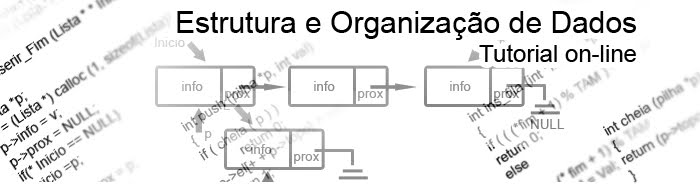
Listas Duplamente Encadeadas
A lista duplamente encadeada possui maior facilidade de acesso aos nós da lista possibilitando uma maior manipulação das informações e da própria lista. Esse conceito utiliza os mesmos conceitos de listas vistos, porém a lista possui outro ponteiro que auxilia na busca das informações na lista.
struct no
{
struct no * esq;
int info;
struct no *dir;
}; typedef struct no lista
É necessário redefinir a estrutura do nó da lista com um novo ponteiro que irá apontar para o nó anterior e com isso interligará a lista em que pode obter uma busca tanto para direita da lista como para a esquerda da lista.
O nó duplamente encadeado possui a vantagem de auxiliar o programador nas implementações da lista em que agora tem uma maior facilidade de encontrar informações dentro da lista.
void cria_listadupla (Lista * * inicio, Lista * * fim)
{
*inicio = NULL;
*fim = NULL;
}

Na criação da lista continua com o conceito de lista encadeada em que os ponteiros “inicio” e “fim” permanecem com valores nulos para a que a lista possa ser iniciada.
Para inserir novos valores na lista duplamente encadeada é necessário que os ponteiros que apontam para o próximo nó e para o anterior estejam devidamente programados para que a lista não possua ponteiros inutilizados com a inserção de novos nós.
void ins_inicio (Lista * * inicio, Lista * * fim, int v)
{
Lista * p;
p = (Lista * ) calloc (1, sizeof (Lista));
p-> info = v;
p-> esq = NULL;
p-> dir = *inicio;
if (*inicio = = NULL)
*fim = p;
else
(*inicio)-> esq = p;
*Inicio =p;
}
Esse método de inserção de valores insere novos valores no inicio da lista em que agora é preciso que o novo ponteiro que aponta para o nó anterior precisa ser definido. O ponteiro “p” que aponta “esq” recebe um valor nulo, pois caracteriza como o inicio da lista e não possui outros valores anteriores ao primeiro nó.
No caso de inserir novos valores o método verifica se a lista já possui algum nó na lista, caso não exista o nó a ser inserido é o primeiro e os ponteiros “inicio” e “fim” estarão no primeiro nó, porém caso já exista algum nó na lista o ponteiro “esq” irá apontar para o nó anterior que está sendo inserido na lista o ponteiro “inicio” auxilia a definir o nó como primeiro e novo nó pode ser acoplado à lista.
void ins_fim (Lista * *inicio, Lista * *fim, int v)
{
Lista *p;
p = (Lista *) calloc (1,sizeof(Lista));
p-> info = v;
p-> dir = NULL;
p-> esq = *fim;
if (*inicio == NULL)
*inicio = p;
Else
(*fim)-> dir = p;
*fim = p;
}
O método de implementação descrito insere novos valores no final da lista em que o ponteiro “dir” nesse caso será atribuído o valor nulo para identificar o nó como o último nó da lista.
É também verificado se a lista já possui algum nó com isso é analisado se o ponteiro “inicio” está apontando para algum nó, se não estiver apontando, ou seja, o ponteiro “inicio” é nulo, então significa que a lista não contem nó e então o ponteiro “inicio” e “fim” estarão no primeiro nó da lista, no entanto se o ponteiro “inicio” não é “nulo” então o ponteiro “dir” apontará para o próximo nó da lista com o auxílio do ponteiro “fim” e por fim o novo nó inserido será o último nó da lista.
A lista duplamente encadeada é o melhor método de listas visto que facilita o programador na implementação de métodos que aumentam a capacidade de armazenar mais informações da lista de forma que essas informações possam ser encontradas com uma maior praticidade e também na organização dessas informações.

struct no
{
struct no * esq;
int info;
struct no *dir;
}; typedef struct no lista
É necessário redefinir a estrutura do nó da lista com um novo ponteiro que irá apontar para o nó anterior e com isso interligará a lista em que pode obter uma busca tanto para direita da lista como para a esquerda da lista.
O nó duplamente encadeado possui a vantagem de auxiliar o programador nas implementações da lista em que agora tem uma maior facilidade de encontrar informações dentro da lista.
void cria_listadupla (Lista * * inicio, Lista * * fim)
{
*inicio = NULL;
*fim = NULL;
}

Na criação da lista continua com o conceito de lista encadeada em que os ponteiros “inicio” e “fim” permanecem com valores nulos para a que a lista possa ser iniciada.
Para inserir novos valores na lista duplamente encadeada é necessário que os ponteiros que apontam para o próximo nó e para o anterior estejam devidamente programados para que a lista não possua ponteiros inutilizados com a inserção de novos nós.
void ins_inicio (Lista * * inicio, Lista * * fim, int v)
{
Lista * p;
p = (Lista * ) calloc (1, sizeof (Lista));
p-> info = v;
p-> esq = NULL;
p-> dir = *inicio;
if (*inicio = = NULL)
*fim = p;
else
(*inicio)-> esq = p;
*Inicio =p;
}
Esse método de inserção de valores insere novos valores no inicio da lista em que agora é preciso que o novo ponteiro que aponta para o nó anterior precisa ser definido. O ponteiro “p” que aponta “esq” recebe um valor nulo, pois caracteriza como o inicio da lista e não possui outros valores anteriores ao primeiro nó.
No caso de inserir novos valores o método verifica se a lista já possui algum nó na lista, caso não exista o nó a ser inserido é o primeiro e os ponteiros “inicio” e “fim” estarão no primeiro nó, porém caso já exista algum nó na lista o ponteiro “esq” irá apontar para o nó anterior que está sendo inserido na lista o ponteiro “inicio” auxilia a definir o nó como primeiro e novo nó pode ser acoplado à lista.
void ins_fim (Lista * *inicio, Lista * *fim, int v)
{
Lista *p;
p = (Lista *) calloc (1,sizeof(Lista));
p-> info = v;
p-> dir = NULL;
p-> esq = *fim;
if (*inicio == NULL)
*inicio = p;
Else
(*fim)-> dir = p;
*fim = p;
}
O método de implementação descrito insere novos valores no final da lista em que o ponteiro “dir” nesse caso será atribuído o valor nulo para identificar o nó como o último nó da lista.
É também verificado se a lista já possui algum nó com isso é analisado se o ponteiro “inicio” está apontando para algum nó, se não estiver apontando, ou seja, o ponteiro “inicio” é nulo, então significa que a lista não contem nó e então o ponteiro “inicio” e “fim” estarão no primeiro nó da lista, no entanto se o ponteiro “inicio” não é “nulo” então o ponteiro “dir” apontará para o próximo nó da lista com o auxílio do ponteiro “fim” e por fim o novo nó inserido será o último nó da lista.
A lista duplamente encadeada é o melhor método de listas visto que facilita o programador na implementação de métodos que aumentam a capacidade de armazenar mais informações da lista de forma que essas informações possam ser encontradas com uma maior praticidade e também na organização dessas informações.

Assinar:
Postagens (Atom)
