









A dúvida foi:
"Olá Henrique,
sou estudante de computação e na materia de estrutura de dados estamos nessa parte de fila. Tem algumas coisas que eu nao estendi nesse seu código, como por exemplo porque faz: if ( ( (*fim + 1) % TAM ) = = * inicio)
o que tem a ver esse mod(%) pelo tamanho??
Obrigada
Carolina"
Primeiramente obrigado por comentar no blog que visa auxiliar as dúvidas dos internautas.
Respondendo a sua dúvida.
Esse if verifica se a fila está cheia para no caso não inserir elementos na fila.
( ( (*fim + 1) % TAM ) = = * inicio)
Vendo que os ponteiros fim e inicio foram iniciados vazios na fila_vazia:
void fila_vazia (int *i, int *f)
{
*i = 0;
*f = 0;
}
Podemos interpretar o if de outra maneira caso não possua nenhum elemento.
( ( (0 + 1) % 10 ) = = 0)
Em que o resto da divisão de 1 por 10 é 1 diz que essa condição é falsa.
Agora o porque de usar o mod(%) pelo tamanho?
Isso é usado para ver se o parâmetro *fim está com a quantidade máxima de elementos que ela pode receber.
Como o TAM é 10 e a cada nova inserção é adicionado ao ponteiro *fim um valor além do que foi inserido anteriormente na condição else (*fim = (* fim + 1) % TAM;).
Se for inserido 10 elementos na fila a condição if passa a ser:
( ( (9 + 1) % 10 ) = = 0)
O resto da divisão de 10 por 10 é zero que é igual ao ponteiro de início.
Espero ter respondido a sua dúvida e continue a comentar no blog.
Muito Obrigado Carolina fique com Deus.
segunda-feira, 14 de junho de 2010
quarta-feira, 19 de maio de 2010
Referências
Segue aqui as referências para o desenvolvimento desse tutorial.
VELOSO, Paulo et al. Estrutura de dados. Rio de Janeiro: Campus, 1983.
PEREIRA, Silvio do Lago. Estruturas de dados fundamentais. São Paulo: Érica, 2009.
TENENBAUM, Aaron M.; LANGSAM, Yedidyah; AUGENSTEIN, Moshe J.; Estruturas de dados usando C. São Paulo: Makron Books, 1995.
DUARTE, Kátia; Tutorial Linguagem C – Matrizes. S.L 2005. Disponível em: http://www.juliobattisti.com.br/tutoriais/katiaduarte/cbasico004.asp
PINHO, Márcio Sarroglia; Material de consulta de Linguagem C. Porto Alegre PUCRS, S.D. Disponível em: http://www.inf.pucrs.br/~pinho/LaproI/Vetores/Vetores.htm#ExemplosVet
MANSSOUR, Isabel Harb; Linguagem de Programação C. Porto Alegre PUCRS, 2001. Disponível em: http://www.inf.pucrs.br/~manssour/LinguagemC
SCHILDT, Herbert apud MANSSOUR, Isabel Harb. C Completo e total. São Paulo: Makron Books, 1996.
SOULIE, Juan; C++ Language Tutorial. S.L, 2009. Disponível em: http://www.cplusplus.com/doc/tutorial/
TESSLER, Eduardo; O que é e pra que serve a Internet? S. L 2009. Disponível em: http://www.midiamundo.com/2009/09/o-que-e-e-para-que-serve-internet.html
MOTA, Kleber; Estruturas de dados – conceitos básicos. S.L, 2009. Disponível em: http://www.klebermota.eti.br/2009/08/estrutura-de-dados-conceitos-basicos/
SUAVÉ, Jacques Philippe; Estruturas de dados – tipos de coleções. Campina Grande UFCG, 2007. Disponível em: http://www.dsc.ufcg.edu.br/~jacques/cursos/p2/html/ed/colecoes.htm
FEOFILOFF, Paulo; Linguagem C: struct. São Paulo USP, 2008. Disónível em: http://www.ime.usp.br/~pf/algoritmos/aulas/stru.html
DUARTE, Kátia; Tutorial Linguagem C – Alocação Dinâmica. S.L 2006. Disponível em: http://www.juliobattisti.com.br/tutoriais/katiaduarte/cbasico009.asp
VELOSO, Paulo et al. Estrutura de dados. Rio de Janeiro: Campus, 1983.
PEREIRA, Silvio do Lago. Estruturas de dados fundamentais. São Paulo: Érica, 2009.
TENENBAUM, Aaron M.; LANGSAM, Yedidyah; AUGENSTEIN, Moshe J.; Estruturas de dados usando C. São Paulo: Makron Books, 1995.
DUARTE, Kátia; Tutorial Linguagem C – Matrizes. S.L 2005. Disponível em: http://www.juliobattisti.com.br/tutoriais/katiaduarte/cbasico004.asp
PINHO, Márcio Sarroglia; Material de consulta de Linguagem C. Porto Alegre PUCRS, S.D. Disponível em: http://www.inf.pucrs.br/~pinho/LaproI/Vetores/Vetores.htm#ExemplosVet
MANSSOUR, Isabel Harb; Linguagem de Programação C. Porto Alegre PUCRS, 2001. Disponível em: http://www.inf.pucrs.br/~manssour/LinguagemC
SCHILDT, Herbert apud MANSSOUR, Isabel Harb. C Completo e total. São Paulo: Makron Books, 1996.
SOULIE, Juan; C++ Language Tutorial. S.L, 2009. Disponível em: http://www.cplusplus.com/doc/tutorial/
TESSLER, Eduardo; O que é e pra que serve a Internet? S. L 2009. Disponível em: http://www.midiamundo.com/2009/09/o-que-e-e-para-que-serve-internet.html
MOTA, Kleber; Estruturas de dados – conceitos básicos. S.L, 2009. Disponível em: http://www.klebermota.eti.br/2009/08/estrutura-de-dados-conceitos-basicos/
SUAVÉ, Jacques Philippe; Estruturas de dados – tipos de coleções. Campina Grande UFCG, 2007. Disponível em: http://www.dsc.ufcg.edu.br/~jacques/cursos/p2/html/ed/colecoes.htm
FEOFILOFF, Paulo; Linguagem C: struct. São Paulo USP, 2008. Disónível em: http://www.ime.usp.br/~pf/algoritmos/aulas/stru.html
DUARTE, Kátia; Tutorial Linguagem C – Alocação Dinâmica. S.L 2006. Disponível em: http://www.juliobattisti.com.br/tutoriais/katiaduarte/cbasico009.asp
terça-feira, 18 de maio de 2010
Filas
A fila é um dos métodos em estruturas de dados em que possui conceitos de inserir e remover dados junto com o conceito de pilhas e listas porém a fila é independente desses métodos de implementação devido ao seu funcionamento.

A organização das filas se iguala as filas convencionais que estão presentes no cotidiano visto que a fila funciona na ordem de que o as pessoas entram no fim da fila e as pessoas saem no começo da fila. (PEREIRA, 2009).
As filas funcionam em esquema de FIFO (First In – First Out), ou seja, primeiro que entra e o último que sai visto na figura a seguir. (PEREIRA, 2009).

Tenenbaum; Langsam; Augenstein; (1995, p.207) afirma que uma fila é um conjunto ordenado de itens a partir do qual pode-se eliminar itens numa extremidade (chamada início da fila) e no qual pode-se inserir itens na outra extremidade (chamada final da fila).
As filas utilizam uma estrutura similar ao conceito de pilhas porem possui um novo parâmetro auxiliar que indica o fim da fila.
#define TAM 10
typedef struct
{
int inicio[TAM];
int fim;
}; fila;
As filas são similares a uma lista circular, em que a variável auxiliar “inicio” encontra-se na mesma posição da variável “fim” ao iniciar a fila.
void fila_vazia (int *i, int *f)
{
*i = 0;
*f = 0;
}
A fila inicia vazia recebendo os parâmetros auxiliares de sua estrutura “inicio” e “fim”, esses dois parâmetros recebem valor “0” de modo que esses parâmetros auxiliarem inicia-se juntos pertencentes à fila.
Para realizar a inclusão ou a remoção de informação da fila é necessário que as variáveis auxiliares sejam bem definidas para que a fila funcione corretamente.
int ins_fila (int *fila, int *inicio, int *fim, int val)
{
if ( ( (*fim + 1) % TAM ) = = * inicio)
return 0;
else
{
*fim = (* fim + 1) % TAM;
fila [* fim ] = Val;
return 1;
}
}
O método de inserir elementos recebe como parâmetros a estrutura da fila, as variáveis “inicio” e “fim” para manipular a informação e recebe a informação que será inserida. Para realizar a inclusão é verificado se a fila já esta cheia, se a variável “fim“ obtiver o mesmo tamanho que a variável “inicio” quer dizer que a fila está cheia e a operação não é concluída, agora no caso das variáveis não serem iguais nos seus valores a variável “fim” recebe um acréscimo no seu valor e em seguida a fila na posição da variável “fim” recebe a informação e o método conclui com sucesso.
Int rem_fila (int * fila, int *inicio, int *fim, int *val)
{
If ( *fim = = * inicio)
return 0;
else
{
*inicio = (* inicio + 1 ) % TAM;
*val = fila[* inicio];
return 1;
}
}
O método de remover as informações da fila possui um método de verificar diferenciado do método de incluir, pois a inclusão verifica se a lista está cheia analisando se os seus valores estão iguais ao valor definido “TAM” e o método de remover verifica se os dois valores são iguais sendo que são “0” ou seja, a fila não possui nenhuma informação e a operação de remoção não é concluída, caso a fila possua algum elemento o ponteiro inicio recebe um acréscimo no seu valor e depois o valor é removido da fila.

A organização das filas se iguala as filas convencionais que estão presentes no cotidiano visto que a fila funciona na ordem de que o as pessoas entram no fim da fila e as pessoas saem no começo da fila. (PEREIRA, 2009).
As filas funcionam em esquema de FIFO (First In – First Out), ou seja, primeiro que entra e o último que sai visto na figura a seguir. (PEREIRA, 2009).

Tenenbaum; Langsam; Augenstein; (1995, p.207) afirma que uma fila é um conjunto ordenado de itens a partir do qual pode-se eliminar itens numa extremidade (chamada início da fila) e no qual pode-se inserir itens na outra extremidade (chamada final da fila).
As filas utilizam uma estrutura similar ao conceito de pilhas porem possui um novo parâmetro auxiliar que indica o fim da fila.
#define TAM 10
typedef struct
{
int inicio[TAM];
int fim;
}; fila;
As filas são similares a uma lista circular, em que a variável auxiliar “inicio” encontra-se na mesma posição da variável “fim” ao iniciar a fila.
void fila_vazia (int *i, int *f)
{
*i = 0;
*f = 0;
}
A fila inicia vazia recebendo os parâmetros auxiliares de sua estrutura “inicio” e “fim”, esses dois parâmetros recebem valor “0” de modo que esses parâmetros auxiliarem inicia-se juntos pertencentes à fila.
Para realizar a inclusão ou a remoção de informação da fila é necessário que as variáveis auxiliares sejam bem definidas para que a fila funcione corretamente.
int ins_fila (int *fila, int *inicio, int *fim, int val)
{
if ( ( (*fim + 1) % TAM ) = = * inicio)
return 0;
else
{
*fim = (* fim + 1) % TAM;
fila [* fim ] = Val;
return 1;
}
}
O método de inserir elementos recebe como parâmetros a estrutura da fila, as variáveis “inicio” e “fim” para manipular a informação e recebe a informação que será inserida. Para realizar a inclusão é verificado se a fila já esta cheia, se a variável “fim“ obtiver o mesmo tamanho que a variável “inicio” quer dizer que a fila está cheia e a operação não é concluída, agora no caso das variáveis não serem iguais nos seus valores a variável “fim” recebe um acréscimo no seu valor e em seguida a fila na posição da variável “fim” recebe a informação e o método conclui com sucesso.
Int rem_fila (int * fila, int *inicio, int *fim, int *val)
{
If ( *fim = = * inicio)
return 0;
else
{
*inicio = (* inicio + 1 ) % TAM;
*val = fila[* inicio];
return 1;
}
}
O método de remover as informações da fila possui um método de verificar diferenciado do método de incluir, pois a inclusão verifica se a lista está cheia analisando se os seus valores estão iguais ao valor definido “TAM” e o método de remover verifica se os dois valores são iguais sendo que são “0” ou seja, a fila não possui nenhuma informação e a operação de remoção não é concluída, caso a fila possua algum elemento o ponteiro inicio recebe um acréscimo no seu valor e depois o valor é removido da fila.
Pilhas
As pilhas são implementações parecidas com as listas em que a pilha possui uma maior organização de suas informações e também conceitos que facilitam o entendimento do programador.
Tenenbaum; Langsam; Augenstein; (1995, p.86) argumentam que uma pilha é conjunto ordenado de itens em que novos itens podem ser inseridos e a partir do qual podem ser eliminados itens em uma extremidade chamada de topo da pilha. Ao contrário do que acontece com o vetor, a definição da pilha compreende a inserção e a eliminação de itens, de modo que uma é um objeto dinâmico, constantemente mutável.

A implementação de pilha coloca novos elementos no seu topo e apenas a informação do topo da lista pode ser removido, a pilha utiliza a política de acesso LIFO (Last-In First Out) significa que o último elemento inserido deve ser o primeiro a ser removido. (PEREIRA, 2009).

A pilha possui a vantagem de poder limitar a quantidade de elementos que estão contidos, com isso ela é similar a um vetor de tamanho definido e também a uma lista encadeada. Há várias vantagens no método de pilha em que é possível criar históricos de páginas visitadas e também comando de desfazer em editores de texto.
O método de criar uma pilha é similar ao conceito de lista em que utiliza o conceito de “struct” ou um registro para iniciar a pilha.
#define TAM 10
typedef struct
{
int topo;
int el[TAM];
}; pilha
A estrutura da pilha funciona com o seu topo que é o primeiro elemento da pilha e indica a posição que a informação está e em seguida o vetor “el” recebe as informações e somente obterá novas informações até chegar ao valor definido em “TAM”.
Como visto a pilha tem o topo como primeiro elemento, com isso a pilha é iniciada a partir do topo igual a -1 pois o vetor tem seu elemento 0 como primeiro valor válido.
void inicia (pilha *p)
{
p-> topo = -1;
}
A pilha é iniciada tendo como parâmetro o ponteiro “p” em que auxiliará na organização de entrada de novas informações na pilha. O topo é iniciado na posição “-1” é necessário que o programador entenda que não é atribuído valores ou informações aos ponteiros, mas sim ao endereço em que o topo se encontra, esse valor de endereço “-1” é utilizado para que seja possível equalizar os valores de tamanho da pilha.
Para implementações nas pilhas como inserir ou retirar valores é necessário para o desenvolvimento dos algoritmos ou programas verifiquem se a pilha está cheia ou vazia, pois a pilha possui um tamanho limite de informações que ela pode receber e para o caso de estar vazia e se estiver cheia o comando de inserir não acontecerá.
int cheia (pilha *p)
{
return (p->topo = = TAM –1);
}
Esse método verificará se a pilha está cheia, para isso o é utilizado o método do tipo int no qual é possível retornar informações através do comando “return” no caso da condição que o comando “return” possui seja verdadeiro a condição que o método “cheia” esteja não será possível inserir novos valores na pilha.
int vazia (pilha *p)
{
Return (p->topo = = -1);
}
O método descrito verifica se a pilha está vazia, em que a condição dentro do comando “return” for verdadeira quer dizer que a pilha está realmente vazia pois o “p->topo” iniciou com o valor “-1” justamente para ter a possibilidade de verificar se existe elementos na lista e poder acrescentar até o limite de elementos “TAM”.
Os métodos de inserir e remover valores na pilha são demonstrados como “push” e “pop” em que o comando “push” acrescentará novas informações e “pop” removerá as informações.
Com isso foi necessário os métodos de verificar se a lista está cheia ou vazia para possibilitar o funcionamento dos comandos “push” e “pop”.
int push (pilha *p, int val)
{
if ( cheia ( p ) )
return 0;
p->el[+ + p->topo] = val;
return 1;
}
O comando “push” insere um novo valor na pilha, em que ele pega o parâmetro da pilha e da informação a que será inserida após isso o comando verifica se a pilha está cheia através do método “cheia” que foi argumentado, caso a pilha esteja sem espaço para novos elementos ela retornará “0” no qual diz que a pilha está completa, caso a condição seja falsa a variável que determina a quantidade de elementos da pilha “el” receberá a nova informação no topo da pilha e retornará “1” em que confirma a operação na pilha.
int pop (pilha *p, int *val)
{
if ( vazia ( p ) )
return 0;
*val = p->el [p->topo - - ];
return 1;
}
Esse método “pop” remove as informações contidas na pilha, de modo o valor agora é preciso ser passado como parâmetro para possibilitar a remoção da informação. É preciso que o comando de remoção verifique se a pilha está vazia para realizar a sua operação, se a pilha estiver vazia o método não remove a informação e se a pilha contiver elementos o comando remove o elemento da pilha em que a informação removida é a primeira da lista.
A pilha pode ser manipulada pelos comandos “push” e “pop” que realizam grande funcionalidade para a pilha. Em suma a pilha é um método de inserção e remoção de dados mais apurada que as listas.
Tenenbaum; Langsam; Augenstein; (1995, p.86) argumentam que uma pilha é conjunto ordenado de itens em que novos itens podem ser inseridos e a partir do qual podem ser eliminados itens em uma extremidade chamada de topo da pilha. Ao contrário do que acontece com o vetor, a definição da pilha compreende a inserção e a eliminação de itens, de modo que uma é um objeto dinâmico, constantemente mutável.

A implementação de pilha coloca novos elementos no seu topo e apenas a informação do topo da lista pode ser removido, a pilha utiliza a política de acesso LIFO (Last-In First Out) significa que o último elemento inserido deve ser o primeiro a ser removido. (PEREIRA, 2009).

A pilha possui a vantagem de poder limitar a quantidade de elementos que estão contidos, com isso ela é similar a um vetor de tamanho definido e também a uma lista encadeada. Há várias vantagens no método de pilha em que é possível criar históricos de páginas visitadas e também comando de desfazer em editores de texto.
O método de criar uma pilha é similar ao conceito de lista em que utiliza o conceito de “struct” ou um registro para iniciar a pilha.
#define TAM 10
typedef struct
{
int topo;
int el[TAM];
}; pilha
A estrutura da pilha funciona com o seu topo que é o primeiro elemento da pilha e indica a posição que a informação está e em seguida o vetor “el” recebe as informações e somente obterá novas informações até chegar ao valor definido em “TAM”.
Como visto a pilha tem o topo como primeiro elemento, com isso a pilha é iniciada a partir do topo igual a -1 pois o vetor tem seu elemento 0 como primeiro valor válido.
void inicia (pilha *p)
{
p-> topo = -1;
}
A pilha é iniciada tendo como parâmetro o ponteiro “p” em que auxiliará na organização de entrada de novas informações na pilha. O topo é iniciado na posição “-1” é necessário que o programador entenda que não é atribuído valores ou informações aos ponteiros, mas sim ao endereço em que o topo se encontra, esse valor de endereço “-1” é utilizado para que seja possível equalizar os valores de tamanho da pilha.
Para implementações nas pilhas como inserir ou retirar valores é necessário para o desenvolvimento dos algoritmos ou programas verifiquem se a pilha está cheia ou vazia, pois a pilha possui um tamanho limite de informações que ela pode receber e para o caso de estar vazia e se estiver cheia o comando de inserir não acontecerá.
int cheia (pilha *p)
{
return (p->topo = = TAM –1);
}
Esse método verificará se a pilha está cheia, para isso o é utilizado o método do tipo int no qual é possível retornar informações através do comando “return” no caso da condição que o comando “return” possui seja verdadeiro a condição que o método “cheia” esteja não será possível inserir novos valores na pilha.
int vazia (pilha *p)
{
Return (p->topo = = -1);
}
O método descrito verifica se a pilha está vazia, em que a condição dentro do comando “return” for verdadeira quer dizer que a pilha está realmente vazia pois o “p->topo” iniciou com o valor “-1” justamente para ter a possibilidade de verificar se existe elementos na lista e poder acrescentar até o limite de elementos “TAM”.
Os métodos de inserir e remover valores na pilha são demonstrados como “push” e “pop” em que o comando “push” acrescentará novas informações e “pop” removerá as informações.
Com isso foi necessário os métodos de verificar se a lista está cheia ou vazia para possibilitar o funcionamento dos comandos “push” e “pop”.
int push (pilha *p, int val)
{
if ( cheia ( p ) )
return 0;
p->el[+ + p->topo] = val;
return 1;
}
O comando “push” insere um novo valor na pilha, em que ele pega o parâmetro da pilha e da informação a que será inserida após isso o comando verifica se a pilha está cheia através do método “cheia” que foi argumentado, caso a pilha esteja sem espaço para novos elementos ela retornará “0” no qual diz que a pilha está completa, caso a condição seja falsa a variável que determina a quantidade de elementos da pilha “el” receberá a nova informação no topo da pilha e retornará “1” em que confirma a operação na pilha.
int pop (pilha *p, int *val)
{
if ( vazia ( p ) )
return 0;
*val = p->el [p->topo - - ];
return 1;
}
Esse método “pop” remove as informações contidas na pilha, de modo o valor agora é preciso ser passado como parâmetro para possibilitar a remoção da informação. É preciso que o comando de remoção verifique se a pilha está vazia para realizar a sua operação, se a pilha estiver vazia o método não remove a informação e se a pilha contiver elementos o comando remove o elemento da pilha em que a informação removida é a primeira da lista.
A pilha pode ser manipulada pelos comandos “push” e “pop” que realizam grande funcionalidade para a pilha. Em suma a pilha é um método de inserção e remoção de dados mais apurada que as listas.
Listas Duplamente Encadeadas
A lista duplamente encadeada possui maior facilidade de acesso aos nós da lista possibilitando uma maior manipulação das informações e da própria lista. Esse conceito utiliza os mesmos conceitos de listas vistos, porém a lista possui outro ponteiro que auxilia na busca das informações na lista.
struct no
{
struct no * esq;
int info;
struct no *dir;
}; typedef struct no lista
É necessário redefinir a estrutura do nó da lista com um novo ponteiro que irá apontar para o nó anterior e com isso interligará a lista em que pode obter uma busca tanto para direita da lista como para a esquerda da lista.
O nó duplamente encadeado possui a vantagem de auxiliar o programador nas implementações da lista em que agora tem uma maior facilidade de encontrar informações dentro da lista.
void cria_listadupla (Lista * * inicio, Lista * * fim)
{
*inicio = NULL;
*fim = NULL;
}

Na criação da lista continua com o conceito de lista encadeada em que os ponteiros “inicio” e “fim” permanecem com valores nulos para a que a lista possa ser iniciada.
Para inserir novos valores na lista duplamente encadeada é necessário que os ponteiros que apontam para o próximo nó e para o anterior estejam devidamente programados para que a lista não possua ponteiros inutilizados com a inserção de novos nós.
void ins_inicio (Lista * * inicio, Lista * * fim, int v)
{
Lista * p;
p = (Lista * ) calloc (1, sizeof (Lista));
p-> info = v;
p-> esq = NULL;
p-> dir = *inicio;
if (*inicio = = NULL)
*fim = p;
else
(*inicio)-> esq = p;
*Inicio =p;
}
Esse método de inserção de valores insere novos valores no inicio da lista em que agora é preciso que o novo ponteiro que aponta para o nó anterior precisa ser definido. O ponteiro “p” que aponta “esq” recebe um valor nulo, pois caracteriza como o inicio da lista e não possui outros valores anteriores ao primeiro nó.
No caso de inserir novos valores o método verifica se a lista já possui algum nó na lista, caso não exista o nó a ser inserido é o primeiro e os ponteiros “inicio” e “fim” estarão no primeiro nó, porém caso já exista algum nó na lista o ponteiro “esq” irá apontar para o nó anterior que está sendo inserido na lista o ponteiro “inicio” auxilia a definir o nó como primeiro e novo nó pode ser acoplado à lista.
void ins_fim (Lista * *inicio, Lista * *fim, int v)
{
Lista *p;
p = (Lista *) calloc (1,sizeof(Lista));
p-> info = v;
p-> dir = NULL;
p-> esq = *fim;
if (*inicio == NULL)
*inicio = p;
Else
(*fim)-> dir = p;
*fim = p;
}
O método de implementação descrito insere novos valores no final da lista em que o ponteiro “dir” nesse caso será atribuído o valor nulo para identificar o nó como o último nó da lista.
É também verificado se a lista já possui algum nó com isso é analisado se o ponteiro “inicio” está apontando para algum nó, se não estiver apontando, ou seja, o ponteiro “inicio” é nulo, então significa que a lista não contem nó e então o ponteiro “inicio” e “fim” estarão no primeiro nó da lista, no entanto se o ponteiro “inicio” não é “nulo” então o ponteiro “dir” apontará para o próximo nó da lista com o auxílio do ponteiro “fim” e por fim o novo nó inserido será o último nó da lista.
A lista duplamente encadeada é o melhor método de listas visto que facilita o programador na implementação de métodos que aumentam a capacidade de armazenar mais informações da lista de forma que essas informações possam ser encontradas com uma maior praticidade e também na organização dessas informações.

struct no
{
struct no * esq;
int info;
struct no *dir;
}; typedef struct no lista
É necessário redefinir a estrutura do nó da lista com um novo ponteiro que irá apontar para o nó anterior e com isso interligará a lista em que pode obter uma busca tanto para direita da lista como para a esquerda da lista.
O nó duplamente encadeado possui a vantagem de auxiliar o programador nas implementações da lista em que agora tem uma maior facilidade de encontrar informações dentro da lista.
void cria_listadupla (Lista * * inicio, Lista * * fim)
{
*inicio = NULL;
*fim = NULL;
}

Na criação da lista continua com o conceito de lista encadeada em que os ponteiros “inicio” e “fim” permanecem com valores nulos para a que a lista possa ser iniciada.
Para inserir novos valores na lista duplamente encadeada é necessário que os ponteiros que apontam para o próximo nó e para o anterior estejam devidamente programados para que a lista não possua ponteiros inutilizados com a inserção de novos nós.
void ins_inicio (Lista * * inicio, Lista * * fim, int v)
{
Lista * p;
p = (Lista * ) calloc (1, sizeof (Lista));
p-> info = v;
p-> esq = NULL;
p-> dir = *inicio;
if (*inicio = = NULL)
*fim = p;
else
(*inicio)-> esq = p;
*Inicio =p;
}
Esse método de inserção de valores insere novos valores no inicio da lista em que agora é preciso que o novo ponteiro que aponta para o nó anterior precisa ser definido. O ponteiro “p” que aponta “esq” recebe um valor nulo, pois caracteriza como o inicio da lista e não possui outros valores anteriores ao primeiro nó.
No caso de inserir novos valores o método verifica se a lista já possui algum nó na lista, caso não exista o nó a ser inserido é o primeiro e os ponteiros “inicio” e “fim” estarão no primeiro nó, porém caso já exista algum nó na lista o ponteiro “esq” irá apontar para o nó anterior que está sendo inserido na lista o ponteiro “inicio” auxilia a definir o nó como primeiro e novo nó pode ser acoplado à lista.
void ins_fim (Lista * *inicio, Lista * *fim, int v)
{
Lista *p;
p = (Lista *) calloc (1,sizeof(Lista));
p-> info = v;
p-> dir = NULL;
p-> esq = *fim;
if (*inicio == NULL)
*inicio = p;
Else
(*fim)-> dir = p;
*fim = p;
}
O método de implementação descrito insere novos valores no final da lista em que o ponteiro “dir” nesse caso será atribuído o valor nulo para identificar o nó como o último nó da lista.
É também verificado se a lista já possui algum nó com isso é analisado se o ponteiro “inicio” está apontando para algum nó, se não estiver apontando, ou seja, o ponteiro “inicio” é nulo, então significa que a lista não contem nó e então o ponteiro “inicio” e “fim” estarão no primeiro nó da lista, no entanto se o ponteiro “inicio” não é “nulo” então o ponteiro “dir” apontará para o próximo nó da lista com o auxílio do ponteiro “fim” e por fim o novo nó inserido será o último nó da lista.
A lista duplamente encadeada é o melhor método de listas visto que facilita o programador na implementação de métodos que aumentam a capacidade de armazenar mais informações da lista de forma que essas informações possam ser encontradas com uma maior praticidade e também na organização dessas informações.

Listas com Parametros Auxiliares
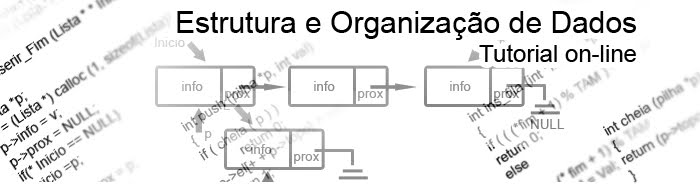
As novas listas possuem a facilidade na busca das informações da lista com o auxilio de ponteiros no fim e no inicio da lista.
A criação da lista muda em que possui um novo parâmetro que estará no final da lista.
void cria (lista * * inicio, lista * * fim)
{
*inicio = NULL;
*fim = NULL;
}
A lista agora possui dois parâmetros que delimitam a lista entre um nó do início (começo da lista) e outro nó no fim (término da lista).
Os métodos de implementar os dados dentro da lista são parecidos com a lista lineares porém agora é preciso que o ponteiro auxiliar “*fim” esteja localizado na lista.
void Inserir_inicio (lista * * Inicio, Lista * * fim, int v)
{
lista *p;
p = (lista * ) calloc (1, sizeof (lista));
p->info = v;
p->prox = * inicio;
if ( * inicio == NULL )
*fim = p;
*inicio = p; }
A lista agora ao inserir uma nova informação precisará verificar se existe algum nó na lista pela condição “if” que verifica se a lista está vazia em que o ponteiro “Inicio” está apontando para um valor nulo com isso o ponteiro “Fim” pode ser inserido na lista.
Caso a lista não tenha nenhum nó os ponteiros “Inicio” e “Fim” estarão no primeiro nó da lista para que esse método de inserção funcione, em que esse método insere os nós no início da lista e então a cada novo nó o ponteiro “Fim” estará no último nó da lista, sendo assim o ponteiro “Inicio” passará para o começo da lista no momento em que o usuário inserir uma nova informação.
Na implementação de novos valores no final da lista também será necessário que o ponteiro “Fim” esteja adequado no método.
void Inserir_Fim (lista * * inicio, lista * * fim, int v)
{
lista *p;
p = (lista *) calloc (1, sizeof(lista))
p->info = v;
p->prox = NULL;
if(* inicio == NULL)
*inicio =p;
else
(*fim)->prox = p;
*fim = p;
}
Esse método ao invés do ponteiro “Inicio” andar quando um novo nó é inserido, agora o ponteiro “Fim” passará para o nó que será inserido na lista.
É verificado se a lista possui algum nó pela condição que o ponteiro “Inicio” não está apontando para nenhum nó, ou seja, ponteiro “Inicio” é igual à “NULL”, se a condição for verdadeira então o ponteiro “Inicio” e o ponteiro “Fim” estarão no mesmo nó ou o primeiro nó da lista, caso a lista já tenha algum nó a condição do “if” será falsa e com isso o nó da posição que o ponteiro “Fim” se encontra apontando para o “prox” estará para a posição que a memória alocada “p” está, em outras palavras o próximo nó será inserido no fim da lista cada vez que esse método for executado.
A lista simplesmente encadeada não apresenta uma grande inovação no conceito de listas. Esse tipo de método de implementar dados somente apresenta um novo parâmetro auxiliar, localizado no fim da lista.

O método de lista simplesmente encadeada é bastante útil em que o programador tem a possibilidade de manipular com mais facilidade a lista que está sendo implementada.
A criação da lista muda em que possui um novo parâmetro que estará no final da lista.
void cria (lista * * inicio, lista * * fim)
{
*inicio = NULL;
*fim = NULL;
}
A lista agora possui dois parâmetros que delimitam a lista entre um nó do início (começo da lista) e outro nó no fim (término da lista).
Os métodos de implementar os dados dentro da lista são parecidos com a lista lineares porém agora é preciso que o ponteiro auxiliar “*fim” esteja localizado na lista.
void Inserir_inicio (lista * * Inicio, Lista * * fim, int v)
{
lista *p;
p = (lista * ) calloc (1, sizeof (lista));
p->info = v;
p->prox = * inicio;
if ( * inicio == NULL )
*fim = p;
*inicio = p; }
A lista agora ao inserir uma nova informação precisará verificar se existe algum nó na lista pela condição “if” que verifica se a lista está vazia em que o ponteiro “Inicio” está apontando para um valor nulo com isso o ponteiro “Fim” pode ser inserido na lista.
Caso a lista não tenha nenhum nó os ponteiros “Inicio” e “Fim” estarão no primeiro nó da lista para que esse método de inserção funcione, em que esse método insere os nós no início da lista e então a cada novo nó o ponteiro “Fim” estará no último nó da lista, sendo assim o ponteiro “Inicio” passará para o começo da lista no momento em que o usuário inserir uma nova informação.
Na implementação de novos valores no final da lista também será necessário que o ponteiro “Fim” esteja adequado no método.
void Inserir_Fim (lista * * inicio, lista * * fim, int v)
{
lista *p;
p = (lista *) calloc (1, sizeof(lista))
p->info = v;
p->prox = NULL;
if(* inicio == NULL)
*inicio =p;
else
(*fim)->prox = p;
*fim = p;
}
Esse método ao invés do ponteiro “Inicio” andar quando um novo nó é inserido, agora o ponteiro “Fim” passará para o nó que será inserido na lista.
É verificado se a lista possui algum nó pela condição que o ponteiro “Inicio” não está apontando para nenhum nó, ou seja, ponteiro “Inicio” é igual à “NULL”, se a condição for verdadeira então o ponteiro “Inicio” e o ponteiro “Fim” estarão no mesmo nó ou o primeiro nó da lista, caso a lista já tenha algum nó a condição do “if” será falsa e com isso o nó da posição que o ponteiro “Fim” se encontra apontando para o “prox” estará para a posição que a memória alocada “p” está, em outras palavras o próximo nó será inserido no fim da lista cada vez que esse método for executado.
A lista simplesmente encadeada não apresenta uma grande inovação no conceito de listas. Esse tipo de método de implementar dados somente apresenta um novo parâmetro auxiliar, localizado no fim da lista.

O método de lista simplesmente encadeada é bastante útil em que o programador tem a possibilidade de manipular com mais facilidade a lista que está sendo implementada.
Listas Simples
As listas são um método de implementar dados ou seja é uma parte da estrutura de dados que auxilia o programador no desenvolvimento do programa. A lista é útil para organizar informações no programa, como listas telefônicas, listas de endereços, entre outras aplicações.
Mota (2009) discute que uma lista é uma estrutura de dados linear. Uma lista ligada, também chamada de encadeada, é linear e dinâmica, é composta por nós que apontam para o próximo elemento da lista, com exceção do último, que não aponta para ninguém. Para compor uma lista encadeada, basta guardar seu primeiro elemento.
É importante que o programador saiba que a lista é uma implementação da uma estrutura de dados, em vez de um tipo de dado, ou seja, a lista é uma estrutura lógica com operações e comandos bem definidos e não é um tipo de dado. (TENENBAUM; LANGSAM; AUGENSTEIN; 1995)
A lista por vetores possui elementos que são organizados de forma linear em que esses elementos possuem um antecessor com a exceção do primeiro valor e o um sucessor com exceção do último valor. (SUAVÉ, 2007).
As listas utilizam o conceito de ponteiros e parâmetros, pois utilizam os endereços da memória para a organização das informações e também para incluí-los ou apagá-los.
Uma lista realiza uma alocação de memória na execução do programa visto que a lista organiza as informações na mesma hora em que o programa está em pleno funcionamento.
Essa alocação é conhecida como alocação dinâmica em que é muito utilizada para solucionar os problemas das estruturas de dados, como em listas, pilhas e filas. Para realizar uma alocação dinâmica é necessário utilizar ponteiros e as funções estão contidas na biblioteca “” (DUARTE, 2006).
p = (int * ) calloc (1, sizeof (int));
O ponteiro “p” que é do tipo int, aloca a memória do computador de tamanho “1” vezes a quantidade de bytes de int.
free(p);
O comando “free” libera a memória que foi alocada pelo ponteiro “p”.
A alocação dinâmica é necessária para começar o desenvolvimento das listas e dos próximos conceitos como listas encadeadas e duplamente encadeadas.
Para entender uma lista é possível que o programador realize uma abstração de como essa estrutura deverá funcionar. Esse tipo de visualização da lista pode ser feita em rascunhos, e com as anotações feitas elas poderão ser úteis em todo o processo de desenvolvimento.
Segundo Tenenbaum; Langsam; Augenstein; (1995, p.224) discutem que a lista pode ser entendida de forma que cada item na lista é chamado de nó e contem dois campos, um campo de informação e um campo de endereço seguinte. O campo de informação armazena o real elemento da lista e o campo do endereço está logo em seguida e possui o endereço do próximo nó na lista. Esse endereço, que é usado pra acessar determinado nó, é conhecido como ponteiro. A lista ligada inteira é acessada a partir de um ponteiro externo que aponta para o endereço que o está o primeiro nó na lista. O campo do próximo endereço do último nó na lista contém um valor especial, conhecido como null, que não é um endereço válido. Esse ponteiro nulo (ou null) é usado para indicar o final de uma lista.
#define
#define
struct no
{
int info;
struct no *prox;
}; typedef struct no lista;

A implementação de um nó (figura ao lado) de uma lista pode ser entendida como uma estrutura em que o campo “info” é reservado para o valor a ser manipulado e logo em seguida o campo “*prox” do tipo struct “no” em que sua posição aponta para o próximo nó da lista possui um ponteiro que pode apontar para outros nós da lista.
Uma lista que não possui nós é chamada de lista vazia ou lista nula com isso os seus ponteiros externos dessa lista serão nulos, a lista pode ser iniciada com valores null. (TENENBAUM; LANGSAM; AUGENSTEIN; 1995).
Lista * cria ( )
{
return NULL;
}
void main( )
{
lista *L;
L = cria( );
}
A implementação de criar uma lista começa com os valores NULL em que o ponteiro “L” do tipo da estrutura “lista” indica o ponteiro de início da lista.
O ponteiro “L” aponta para o ponteiro do tipo lista, em que esse ponteiro passa a ser um valor nulo. Essa implementação é necessária tendo como conceito que a lista para ser iniciada precisa da passagem de ponteiros com isso a função “cria” realiza a operação de iniciar a lista de valor nulo e com passagem de parâmetros
Com a declaração da lista e de suas instruções básicas a lista pode agora armazenar informações.
void inserir_inicio (lista * * L, int v)
{
lista *p = (lista * ) calloc (1, sizeof(lista));
p->info = v;
p->prox = * L;
*L = p;
}
A função de inserção recebe como parâmetros o ponteiro “L” que indica o início da lista e “v” a informação, a ser inserida.
A memória é alocada com o auxílio do ponteiro “p” que indica o novo nó a ser inserido. A informação recebida pelo parâmetro “v” é então atribuído ao campo do novo nó, este novo nó por sua vez tem seu ponteiro “prox” apontando para o início da lista. Para finalizar, o ponteiro “*L” é atualizado junto ao ponteiro auxiliar “p”.
Existe a possibilidade de inserir variáveis no fim da lista para auxiliar o programador na implementação de uma lista.
void inserir_fim (lista * *L, int v)
{
lista *p, *q;
p = (lista *) calloc (1,sizeof (lista));
p->info = v;
p->prox = NULL;
if ( * L == NULL)
*L = p;
else
{
q = *L;
while( q->prox != NULL)
q = q-> prox;
q-> prox = p;
}
}
A função “inserir_fim” possui dois parâmetros que ajudam na manipulação dos nós da lista, o primeiro parâmetro “L” aloca a memória, recebe a informação desejada e aponta para “NULL” que já caracteriza como o fim da lista.
A condição “if” dentro do método é necessária para verificar se a lista possui algum nó, caso o ponteiro “* L” estiver com o valor “NULL” então é interpretado que a lista não possui nenhum nó e com isso pode ser inserida normalmente.
Se a lista possui algum nó será necessário utilizar outra variável “*q” que auxiliará na busca dentro da lista para que o nó possa ser inserido no final. O ponteiro “*q” vai para o início da lista e em seguida um comando de repetição que vai realizar a busca entre os nós da lista, enquanto o próximo nó não for “NULL” ele irá passar de nó em nó até alcançar o último nó da lista. Se a lista possuir um nó ele colocará o próximo nó no final da lista normalmente.
Após a inserção dos elementos na lista, ela pode ser visualizada no compilador em que o programador e o usuário podem analisar as informações inseridas.
void imprime ( lista * L )
{
lista * p;
p = L;
while (p ! = NULL)
{
printf(“%d->”, p->info);
p = p-> prox;
}
Printf(“Null \n”);
getch( );
}
A função que visualiza os dados “imprime”, possui um parâmetro auxiliar em que esse parâmetro enquanto não encontrar o valor “NULL” na lista ele irá para cada nó da lista dentro do comando de repetição e mostrará nó que foi encontrado.

As listas simples lineares são um dos conceitos básicos sobre listas das estruturas de dados, as listas podem servir de grande auxilio para o programador em que podem ser implementadas para organizar diversas informações utilizando o mesmo método para inserir ou manipular dados aos programas ou algoritmos.
Mota (2009) discute que uma lista é uma estrutura de dados linear. Uma lista ligada, também chamada de encadeada, é linear e dinâmica, é composta por nós que apontam para o próximo elemento da lista, com exceção do último, que não aponta para ninguém. Para compor uma lista encadeada, basta guardar seu primeiro elemento.
É importante que o programador saiba que a lista é uma implementação da uma estrutura de dados, em vez de um tipo de dado, ou seja, a lista é uma estrutura lógica com operações e comandos bem definidos e não é um tipo de dado. (TENENBAUM; LANGSAM; AUGENSTEIN; 1995)
A lista por vetores possui elementos que são organizados de forma linear em que esses elementos possuem um antecessor com a exceção do primeiro valor e o um sucessor com exceção do último valor. (SUAVÉ, 2007).
As listas utilizam o conceito de ponteiros e parâmetros, pois utilizam os endereços da memória para a organização das informações e também para incluí-los ou apagá-los.
Uma lista realiza uma alocação de memória na execução do programa visto que a lista organiza as informações na mesma hora em que o programa está em pleno funcionamento.
Essa alocação é conhecida como alocação dinâmica em que é muito utilizada para solucionar os problemas das estruturas de dados, como em listas, pilhas e filas. Para realizar uma alocação dinâmica é necessário utilizar ponteiros e as funções estão contidas na biblioteca “
p = (int * ) calloc (1, sizeof (int));
O ponteiro “p” que é do tipo int, aloca a memória do computador de tamanho “1” vezes a quantidade de bytes de int.
free(p);
O comando “free” libera a memória que foi alocada pelo ponteiro “p”.
A alocação dinâmica é necessária para começar o desenvolvimento das listas e dos próximos conceitos como listas encadeadas e duplamente encadeadas.
Para entender uma lista é possível que o programador realize uma abstração de como essa estrutura deverá funcionar. Esse tipo de visualização da lista pode ser feita em rascunhos, e com as anotações feitas elas poderão ser úteis em todo o processo de desenvolvimento.
Segundo Tenenbaum; Langsam; Augenstein; (1995, p.224) discutem que a lista pode ser entendida de forma que cada item na lista é chamado de nó e contem dois campos, um campo de informação e um campo de endereço seguinte. O campo de informação armazena o real elemento da lista e o campo do endereço está logo em seguida e possui o endereço do próximo nó na lista. Esse endereço, que é usado pra acessar determinado nó, é conhecido como ponteiro. A lista ligada inteira é acessada a partir de um ponteiro externo que aponta para o endereço que o está o primeiro nó na lista. O campo do próximo endereço do último nó na lista contém um valor especial, conhecido como null, que não é um endereço válido. Esse ponteiro nulo (ou null) é usado para indicar o final de uma lista.
#define
#define
struct no
{
int info;
struct no *prox;
}; typedef struct no lista;

A implementação de um nó (figura ao lado) de uma lista pode ser entendida como uma estrutura em que o campo “info” é reservado para o valor a ser manipulado e logo em seguida o campo “*prox” do tipo struct “no” em que sua posição aponta para o próximo nó da lista possui um ponteiro que pode apontar para outros nós da lista.
Uma lista que não possui nós é chamada de lista vazia ou lista nula com isso os seus ponteiros externos dessa lista serão nulos, a lista pode ser iniciada com valores null. (TENENBAUM; LANGSAM; AUGENSTEIN; 1995).
Lista * cria ( )
{
return NULL;
}
void main( )
{
lista *L;
L = cria( );
}
A implementação de criar uma lista começa com os valores NULL em que o ponteiro “L” do tipo da estrutura “lista” indica o ponteiro de início da lista.
O ponteiro “L” aponta para o ponteiro do tipo lista, em que esse ponteiro passa a ser um valor nulo. Essa implementação é necessária tendo como conceito que a lista para ser iniciada precisa da passagem de ponteiros com isso a função “cria” realiza a operação de iniciar a lista de valor nulo e com passagem de parâmetros
Com a declaração da lista e de suas instruções básicas a lista pode agora armazenar informações.
void inserir_inicio (lista * * L, int v)
{
lista *p = (lista * ) calloc (1, sizeof(lista));
p->info = v;
p->prox = * L;
*L = p;
}
A função de inserção recebe como parâmetros o ponteiro “L” que indica o início da lista e “v” a informação, a ser inserida.
A memória é alocada com o auxílio do ponteiro “p” que indica o novo nó a ser inserido. A informação recebida pelo parâmetro “v” é então atribuído ao campo do novo nó, este novo nó por sua vez tem seu ponteiro “prox” apontando para o início da lista. Para finalizar, o ponteiro “*L” é atualizado junto ao ponteiro auxiliar “p”.
Existe a possibilidade de inserir variáveis no fim da lista para auxiliar o programador na implementação de uma lista.
void inserir_fim (lista * *L, int v)
{
lista *p, *q;
p = (lista *) calloc (1,sizeof (lista));
p->info = v;
p->prox = NULL;
if ( * L == NULL)
*L = p;
else
{
q = *L;
while( q->prox != NULL)
q = q-> prox;
q-> prox = p;
}
}
A função “inserir_fim” possui dois parâmetros que ajudam na manipulação dos nós da lista, o primeiro parâmetro “L” aloca a memória, recebe a informação desejada e aponta para “NULL” que já caracteriza como o fim da lista.
A condição “if” dentro do método é necessária para verificar se a lista possui algum nó, caso o ponteiro “* L” estiver com o valor “NULL” então é interpretado que a lista não possui nenhum nó e com isso pode ser inserida normalmente.
Se a lista possui algum nó será necessário utilizar outra variável “*q” que auxiliará na busca dentro da lista para que o nó possa ser inserido no final. O ponteiro “*q” vai para o início da lista e em seguida um comando de repetição que vai realizar a busca entre os nós da lista, enquanto o próximo nó não for “NULL” ele irá passar de nó em nó até alcançar o último nó da lista. Se a lista possuir um nó ele colocará o próximo nó no final da lista normalmente.
Após a inserção dos elementos na lista, ela pode ser visualizada no compilador em que o programador e o usuário podem analisar as informações inseridas.
void imprime ( lista * L )
{
lista * p;
p = L;
while (p ! = NULL)
{
printf(“%d->”, p->info);
p = p-> prox;
}
Printf(“Null \n”);
getch( );
}
A função que visualiza os dados “imprime”, possui um parâmetro auxiliar em que esse parâmetro enquanto não encontrar o valor “NULL” na lista ele irá para cada nó da lista dentro do comando de repetição e mostrará nó que foi encontrado.

As listas simples lineares são um dos conceitos básicos sobre listas das estruturas de dados, as listas podem servir de grande auxilio para o programador em que podem ser implementadas para organizar diversas informações utilizando o mesmo método para inserir ou manipular dados aos programas ou algoritmos.
Ponteiros e Alocação Dinâmica
Para a manipulação do espaço da memória do computador, a linguagem C utiliza parâmetros e ponteiros em que possibilitam a alteração da informação do elemento ou da posição na memória em que o elemento se encontra.
O parâmetro pode ser descrito como uma passagem da informação original pelo valor da variavel e que pode ser utilizada em outras partes do algoritmo, esses parâmetros podem obter a informação do vetor ou de uma variável e transmitir para outra parte do programa, além de transmitir a informação, os parâmetros tem a capacidade de permitir que o algoritmo modifique a variável que será transmitida.
Tenenbaum; Langsam; Augenstein; (1995 p.43) sugerem que o parâmetro de uma função em C precisa ser declarado dentro da função. Entretanto, a faixa de parâmetros de um vetor só é especificada no programa chamador. Isso ocorre porque em C não se aloca novo armazenamento para um parâmetro vetor. Em vez disso, o parâmetro refere-se ao vetor original que estava alocado no programa de chamada.
Para transmitir uma variável ou vetor como parâmetro, é preciso que ele esteja da mesma forma que foi declarado, ele sempre será transmitido como uma referência, então, as alterações realizadas na variável ou nos elementos do vetor altera a variável usada como parâmetro na sua chamada. (PINHO, S.D.).
#define Tam 10
void imprime_vetor (int tam, int vet[Tam])
{
int i;
for (i=0 ; i < Tam ; i++)
printf(“%d”, vet[ i ]);
}
void main( )
{
int Notas[Tam];
imprime_vetor (Tam, Notas);
}
O método “imprime_vetor” pode estar na mesma parte da programação ou em outra parte separada da tela original. Essa passagem dos elementos por parâmetros está somente transmitindo a informação dos valores, ou seja, caso os elementos transmitidos forem alterados eles não sofrerão a alteração na função que os referenciou.
As matrizes também podem ser utilizadas por parâmetros na programação de algoritmos.
#define Lin 5
#define Col 5
void ImprimirDados (mat[lin][col])
{
int i, j;
for (i = 0; i < lin; i ++)
for (j =0; j < col; j ++)
printf(“%d”, mat[ i ][ j ])
}
void main ()
{
int mat[lin][col]
ImprimirDados (mat);
}
Os parâmetros por referência podem transmitir as informações de modo que elas sejam alteradas pelos comandos dentro do algoritmo ou programa.
void acrescenta (int *A)
{
*A = *A + 1;
}
void main ( )
{
int i, vetor[10];
for (i = 0; i < 10; i ++)
acrescenta(&vet[ i ])
}
Na declaração de parâmetros, existe o conceito de ponteiros. Os ponteiros são úteis para fornecer meios para alterar os comandos das funções dos algoritmos ou o conteúdo das variáveis, podem suportar as tarefas de alocação dinâmica que é obter memória ou utilizá-la enquanto está em execução e aumentam o recurso das tarefas dos programas. (MANSSOUR, 2001).
Manssour; (2001) afirma que um ponteiro é uma variável que contém um endereço de memória. Esse endereço é normalmente uma posição de outra variável de memória. Se uma variável contém o endereço de outra, então a primeira variável é dita para apontar para outra como na figura abaixo.

Figura: Uma Variável que aponta para outra (SCHILDT, 1996 apud MANSSOUR, 2001).
O ponteiro possui dois operadores de manipulação e declaração: “&” e “*”. O operador “&” retorna o endereço de memória da variável.
int *a, rec=10;
a = &rec;
A variável “a” recebe o endereço de memória da variável “rec”. É importante entender que a variável “a” não recebe o valor de “rec”, mas sim o lugar em que a variável “rec” se encontra.
O outro operador “*” retorna o valor da variável no endereço localizado, ou seja, os dois operadores podem estar interligados para que funcionem da melhor maneira.
int *a, rec=10, b;
a = &rec;
b = *a;
A variável “b” recebe o valor ou o conteúdo da variável “a” que está localizada na variável “rec”, então a variável “b” terá valor 10.
Os operadores apesar de realizarem um comando parecido eles são distintos, pois um vai à posição em que o se encontra o endereço da variável e o outro recebe o valor em que se encontra o endereço da variável.
Os conceitos de ponteiros e parâmetros são úteis para o desenvolvimento das programações e algoritmos de estruturas de dados, pelo fato que o programador pode manipular a localização da variável na memória, aumentar a capacidade de funções do programa e evitar que erros graves de programação ocorram porem se o programador não dominar ou entender as tarefas que os ponteiros ou parâmetros estão realizando poderá levar a vários erros graves dentro do programa.
Os ponteiros abrangem grande parte das estruturas que podem ser implementadas aos programas ou algoritmos. Um dos conceitos que mais utilizam ponteiros e parâmetros é o conceito de listas.
O parâmetro pode ser descrito como uma passagem da informação original pelo valor da variavel e que pode ser utilizada em outras partes do algoritmo, esses parâmetros podem obter a informação do vetor ou de uma variável e transmitir para outra parte do programa, além de transmitir a informação, os parâmetros tem a capacidade de permitir que o algoritmo modifique a variável que será transmitida.
Tenenbaum; Langsam; Augenstein; (1995 p.43) sugerem que o parâmetro de uma função em C precisa ser declarado dentro da função. Entretanto, a faixa de parâmetros de um vetor só é especificada no programa chamador. Isso ocorre porque em C não se aloca novo armazenamento para um parâmetro vetor. Em vez disso, o parâmetro refere-se ao vetor original que estava alocado no programa de chamada.
Para transmitir uma variável ou vetor como parâmetro, é preciso que ele esteja da mesma forma que foi declarado, ele sempre será transmitido como uma referência, então, as alterações realizadas na variável ou nos elementos do vetor altera a variável usada como parâmetro na sua chamada. (PINHO, S.D.).
#define Tam 10
void imprime_vetor (int tam, int vet[Tam])
{
int i;
for (i=0 ; i < Tam ; i++)
printf(“%d”, vet[ i ]);
}
void main( )
{
int Notas[Tam];
imprime_vetor (Tam, Notas);
}
O método “imprime_vetor” pode estar na mesma parte da programação ou em outra parte separada da tela original. Essa passagem dos elementos por parâmetros está somente transmitindo a informação dos valores, ou seja, caso os elementos transmitidos forem alterados eles não sofrerão a alteração na função que os referenciou.
As matrizes também podem ser utilizadas por parâmetros na programação de algoritmos.
#define Lin 5
#define Col 5
void ImprimirDados (mat[lin][col])
{
int i, j;
for (i = 0; i < lin; i ++)
for (j =0; j < col; j ++)
printf(“%d”, mat[ i ][ j ])
}
void main ()
{
int mat[lin][col]
ImprimirDados (mat);
}
Os parâmetros por referência podem transmitir as informações de modo que elas sejam alteradas pelos comandos dentro do algoritmo ou programa.
void acrescenta (int *A)
{
*A = *A + 1;
}
void main ( )
{
int i, vetor[10];
for (i = 0; i < 10; i ++)
acrescenta(&vet[ i ])
}
Na declaração de parâmetros, existe o conceito de ponteiros. Os ponteiros são úteis para fornecer meios para alterar os comandos das funções dos algoritmos ou o conteúdo das variáveis, podem suportar as tarefas de alocação dinâmica que é obter memória ou utilizá-la enquanto está em execução e aumentam o recurso das tarefas dos programas. (MANSSOUR, 2001).
Manssour; (2001) afirma que um ponteiro é uma variável que contém um endereço de memória. Esse endereço é normalmente uma posição de outra variável de memória. Se uma variável contém o endereço de outra, então a primeira variável é dita para apontar para outra como na figura abaixo.

Figura: Uma Variável que aponta para outra (SCHILDT, 1996 apud MANSSOUR, 2001).
O ponteiro possui dois operadores de manipulação e declaração: “&” e “*”. O operador “&” retorna o endereço de memória da variável.
int *a, rec=10;
a = &rec;
A variável “a” recebe o endereço de memória da variável “rec”. É importante entender que a variável “a” não recebe o valor de “rec”, mas sim o lugar em que a variável “rec” se encontra.
O outro operador “*” retorna o valor da variável no endereço localizado, ou seja, os dois operadores podem estar interligados para que funcionem da melhor maneira.
int *a, rec=10, b;
a = &rec;
b = *a;
A variável “b” recebe o valor ou o conteúdo da variável “a” que está localizada na variável “rec”, então a variável “b” terá valor 10.
Os operadores apesar de realizarem um comando parecido eles são distintos, pois um vai à posição em que o se encontra o endereço da variável e o outro recebe o valor em que se encontra o endereço da variável.
Os conceitos de ponteiros e parâmetros são úteis para o desenvolvimento das programações e algoritmos de estruturas de dados, pelo fato que o programador pode manipular a localização da variável na memória, aumentar a capacidade de funções do programa e evitar que erros graves de programação ocorram porem se o programador não dominar ou entender as tarefas que os ponteiros ou parâmetros estão realizando poderá levar a vários erros graves dentro do programa.
Os ponteiros abrangem grande parte das estruturas que podem ser implementadas aos programas ou algoritmos. Um dos conceitos que mais utilizam ponteiros e parâmetros é o conceito de listas.
sábado, 15 de maio de 2010
Registros
Uma struct é um comando em C que armazena uma coleção de várias variáveis e é possível conter tipos diferentes. É utilizado no conceito de registros em que é possível utilizar a mesma parte dos comandos armazenados em outras partes do programa. Struct é uma abreviação de structures que quer dizer estruturas. (FEOFILOFF, 2008).
A estrutura possui um grupo de itens em que são identificados por um identificador próprio, esses itens são conhecidos como membros da estrutura. Nas linguagens de programação a estrutura pode ser chamada de “registro” e os componentes da estrutura de “campos”. (TENENBAUM; LANGSAM; AUGENSTEIN; 1995).
struct info
{
int dia;
char nome[10];
char endereço[25];
float salário;
} ;
A estrutura (struct) armazena os tipos das variáveis que poderão ser utilizadas diversas vezes pelo programa.
struct info a;
struct info b;
As informações poderão ser armazenadas na estrutura “a” ou na estrutura “b”.
a.dia = 25;
a.nome = ‘Carlos’;
a.endereco = ‘Rua das laranjas’;
a.salario = 340,50;
Na inserção de dados na estrutura é necessário especificar o nome da estrutura para inserir as informações.
A implementação das estruturas em que as variáveis são declaradas como sendo de um determinado tipo, é como dizer que o identificador refere-se a uma determinada parte da memória e que o conteúdo dessa memória é interpretado de acordo o tipo definido.
O tipo especifica a quantidade de memória que está reservada para uma variável e o método em que a memória será interpretada (TENENBAUM; LANGSAM; AUGENSTEIN; 1995).
Os conceitos de endereços de memória são importantes para a manipulação adequada das listas e de implementações de estruturas de dados nos programas ou algoritmos.
A estrutura struct ou registro possui um endereço de memória no computador, e com isso podemos utilizar ponteiros e parâmetros para realizar a implementação de uma estrutura. (FEOFILOFF, 2008).
struct data {
int dia;
int mes;
int ano;
} ;
struct data *p;
struct data a;
p = &a;
(*p).dia = 31;
A estrutura “data *p” é um ponteiro para o registro data, no comando “p = &a” a variável “p” está apontando para “a” ou seja, a estrutura de “p” está no endereço em que a variável “a” se encontra e em seguida o ponteiro “p” que aponta para a variável “dia” e recebe o valor “31”.
p->mes = 8;
p->ano = 2005;
O comando “p->mes” realiza a mesma operação do comando “(*p).mes”.
As estruturas podem ser renomeadas para facilitar o programador na chamada da estrutura em qualquer parte do programa.
struct informacao {
char rua[20];
char bairro[10];
int numero;
} typedef struct informacao endereco;
A instrução “typedef” habilita a nomear a estrutura novamente em que primeiro precisa escrever o nome antigo e em seguida o novo nome para a estrutura.
As estruturas structs ou registros são úteis para realizar formulários, cadastro de clientes, lista de endereços e até uma lista telefônica. As structs podem armazenar uma grande quantidade de informações dependendo do quanto de memória o computador dispõe.
A estrutura possui um grupo de itens em que são identificados por um identificador próprio, esses itens são conhecidos como membros da estrutura. Nas linguagens de programação a estrutura pode ser chamada de “registro” e os componentes da estrutura de “campos”. (TENENBAUM; LANGSAM; AUGENSTEIN; 1995).
struct info
{
int dia;
char nome[10];
char endereço[25];
float salário;
} ;
A estrutura (struct) armazena os tipos das variáveis que poderão ser utilizadas diversas vezes pelo programa.
struct info a;
struct info b;
As informações poderão ser armazenadas na estrutura “a” ou na estrutura “b”.
a.dia = 25;
a.nome = ‘Carlos’;
a.endereco = ‘Rua das laranjas’;
a.salario = 340,50;
Na inserção de dados na estrutura é necessário especificar o nome da estrutura para inserir as informações.
A implementação das estruturas em que as variáveis são declaradas como sendo de um determinado tipo, é como dizer que o identificador refere-se a uma determinada parte da memória e que o conteúdo dessa memória é interpretado de acordo o tipo definido.
O tipo especifica a quantidade de memória que está reservada para uma variável e o método em que a memória será interpretada (TENENBAUM; LANGSAM; AUGENSTEIN; 1995).
Os conceitos de endereços de memória são importantes para a manipulação adequada das listas e de implementações de estruturas de dados nos programas ou algoritmos.
A estrutura struct ou registro possui um endereço de memória no computador, e com isso podemos utilizar ponteiros e parâmetros para realizar a implementação de uma estrutura. (FEOFILOFF, 2008).
struct data {
int dia;
int mes;
int ano;
} ;
struct data *p;
struct data a;
p = &a;
(*p).dia = 31;
A estrutura “data *p” é um ponteiro para o registro data, no comando “p = &a” a variável “p” está apontando para “a” ou seja, a estrutura de “p” está no endereço em que a variável “a” se encontra e em seguida o ponteiro “p” que aponta para a variável “dia” e recebe o valor “31”.
p->mes = 8;
p->ano = 2005;
O comando “p->mes” realiza a mesma operação do comando “(*p).mes”.
As estruturas podem ser renomeadas para facilitar o programador na chamada da estrutura em qualquer parte do programa.
struct informacao {
char rua[20];
char bairro[10];
int numero;
} typedef struct informacao endereco;
A instrução “typedef” habilita a nomear a estrutura novamente em que primeiro precisa escrever o nome antigo e em seguida o novo nome para a estrutura.
As estruturas structs ou registros são úteis para realizar formulários, cadastro de clientes, lista de endereços e até uma lista telefônica. As structs podem armazenar uma grande quantidade de informações dependendo do quanto de memória o computador dispõe.
Matrizes Bidimensionais
A matriz é um vetor bidimensional que armazena informações organizadas em linhas e colunas, porém utiliza o mesmo conceito, de acordo com Tenenbaum; Langsam; Augenstein; (1995 p.47) a matriz ilustra claramente a diferença entre uma visão de dados lógica e uma visão física. Uma matriz é uma estrutura de dados lógica, útil na programação e solução de problemas. Ela ajuda também na organização de um conjunto de valores que dependa de duas entradas.
int A[10][10]
A matriz declarada de nome “A” possui 10 linhas e 10 colunas, para auxiliar o programador a matriz pode ser representada por [ i ][ j ] em que o [ i ] indica o índice de linhas da matriz e o [ j ] o índice de colunas.
É necessário que o programador considere que a organização dos elementos da matriz é parecida com uma tabela.
int B[4][3]

Para a definição das informações da matriz é necessário especificar a posição da linha e da coluna em que será inserido.
int c[2][2]={2,5,3,13}
No processo de armazenar informações dentro de uma matriz, existe a possibilidade de realizar essa inserção usando os comandos da linguagem em que amplia as funcionalidades do programa ou algoritmo.
int i, j, D[5][5]
for (i = 0; i < 5; i ++)
for (j = 0; j < 5; j ++)
D[ i ][ j ] = 5 + i + j;
São necessários dois comandos de repetição “for” para que os elementos possam ser inseridos em todos os espaços da matriz. O primeiro comando de repetição remete a posição da linha em que irá ser inserido e em seguida o segundo comando de repetição passará pelas colunas da matriz e a informação será inserida de coluna em coluna.
O programador tem a opção de definir a quantidade de variáveis da matriz para não perder a quantidade de elementos e poder utilizar esse tamanho definido em outras partes do algoritmo.
#define Lin 10
#define Col 10
int i, j E[Lin][Col]
for (i = 0; i < Lin; i ++)
for (j=0; j < Col; j ++)
E[ i ][ j ] = Lin + Col – j
Na criação de uma matriz também existe a possibilidade do usuário digitar as informações que irá defini-la.
#define Lin 3
#define Col 3
int I, j F[Lin][Col]
for(i=0; i < Lin; i ++)
for (j=0; j < Col; j ++)
scanf(“%d”, &F[ i ][ j ])
Para visualizar os dados inseridos é preciso também utilizar dois comandos de repetição.
#define Lin 10
#define Col 10
int i, j G[Lin][Col]
for(i=0; i < Lin; i ++)
for (j=0; j < Col; j++)
printf(“Linha %d Coluna %d possui o valor: %d”, i, j, E[ i ][ j ])
As matrizes são úteis para organizar listas de registros com endereços, nome e telefone, também é utilizado para armazenar tabelas de preços de vários produtos e organizar as notas semestrais.
Apesar das matrizes poderem armazenar várias informações, ela é limitada a somente um tipo de dado, ou seja, a matriz possui informações exclusivamente de um tipo de variável como “int” ou “float”, mas nunca dos dois tipos.
int A[10][10]
A matriz declarada de nome “A” possui 10 linhas e 10 colunas, para auxiliar o programador a matriz pode ser representada por [ i ][ j ] em que o [ i ] indica o índice de linhas da matriz e o [ j ] o índice de colunas.
É necessário que o programador considere que a organização dos elementos da matriz é parecida com uma tabela.
int B[4][3]

Para a definição das informações da matriz é necessário especificar a posição da linha e da coluna em que será inserido.
int c[2][2]={2,5,3,13}
No processo de armazenar informações dentro de uma matriz, existe a possibilidade de realizar essa inserção usando os comandos da linguagem em que amplia as funcionalidades do programa ou algoritmo.
int i, j, D[5][5]
for (i = 0; i < 5; i ++)
for (j = 0; j < 5; j ++)
D[ i ][ j ] = 5 + i + j;
São necessários dois comandos de repetição “for” para que os elementos possam ser inseridos em todos os espaços da matriz. O primeiro comando de repetição remete a posição da linha em que irá ser inserido e em seguida o segundo comando de repetição passará pelas colunas da matriz e a informação será inserida de coluna em coluna.
O programador tem a opção de definir a quantidade de variáveis da matriz para não perder a quantidade de elementos e poder utilizar esse tamanho definido em outras partes do algoritmo.
#define Lin 10
#define Col 10
int i, j E[Lin][Col]
for (i = 0; i < Lin; i ++)
for (j=0; j < Col; j ++)
E[ i ][ j ] = Lin + Col – j
Na criação de uma matriz também existe a possibilidade do usuário digitar as informações que irá defini-la.
#define Lin 3
#define Col 3
int I, j F[Lin][Col]
for(i=0; i < Lin; i ++)
for (j=0; j < Col; j ++)
scanf(“%d”, &F[ i ][ j ])
Para visualizar os dados inseridos é preciso também utilizar dois comandos de repetição.
#define Lin 10
#define Col 10
int i, j G[Lin][Col]
for(i=0; i < Lin; i ++)
for (j=0; j < Col; j++)
printf(“Linha %d Coluna %d possui o valor: %d”, i, j, E[ i ][ j ])
As matrizes são úteis para organizar listas de registros com endereços, nome e telefone, também é utilizado para armazenar tabelas de preços de vários produtos e organizar as notas semestrais.
Apesar das matrizes poderem armazenar várias informações, ela é limitada a somente um tipo de dado, ou seja, a matriz possui informações exclusivamente de um tipo de variável como “int” ou “float”, mas nunca dos dois tipos.
Vetores ou Matrizes Lineares
O vetor é um conjunto de informações que possui um tamanho definido, ou seja, uma quantidade específica de elementos, o vetor pode ter poucos ou muitos valores, mas é necessária uma quantidade certa de elementos no vetor; os elementos do vetor são distribuídos de forma organizada em que todos os valores ocupam um espaço ordenado dentro do vetor; e esse vetor precisa conter valores do mesmo tipo, por exemplo, o vetor pode ser do tipo inteiro ou caracteres porem não pode possuir esses dois tipos de elementos. (Tenenbaum; Langsam; Augenstein, 1995)
Quando um vetor é declarado, é preciso que o programador entenda a organização em que o vetor foi declarado, para poder manipulá-lo de maneira adequada.
int A[5];

O vetor declarado de nome “A” possui 5 elementos em que somente poderá receber valores do tipo inteiro. Tenebaum; Langsam; Augenstein (1995, p.34) afirmam que mesmo com o vetor especificado não quer dizer que a estrutura de dados está totalmente descrita, com isso é preciso especificar como essa estrutura será acessada.
Para acessar o vetor existe a operação de armazenar alguns elementos dentro do vetor. Essa operação pode ser realizada de diversas maneiras. Uma delas é de definir os valores que serão atribuídos ao vetor logo ao declará-lo.
int b[5] = {2, 10, 13, 6, 37};
O vetor “B”, de 5 elementos que recebe cada valor no seu respectivo lugar declarado, a posição “[0]” indica a primeira posição do vetor e a posição “[4]” indica a última posição do vetor, o vetor “B” possui os seguintes valores “2, 10, 13, 6 e 37”.
As operações de armazenamento podem permitir que o usuário insira os elementos que desejar, com a criação de um índice (variável “i”) e utilizando o comando “for” que repete a operação de inserir os dados até que o vetor esteja completo.
int C[10];
for (i = 0; i <= 9; i++)
{
printf (“Insira o valor na posição %d”, i);
scanf(“%d”, &C[ i ]);
}
O comando “for” repete a operação 10 vezes, mostra na tela uma mensagem ao usuário para que insira um valor do tipo inteiro, após as 10 vezes o comando é finalizado. Essa operação tem um bom uso, mas pode melhorar, pois essa repetição corresponde ao tamanho do vetor e em alguns casos o vetor pode ser definido pelo usuário ou pode ter um tamanho pré-definido em que é utilizado para outras partes do algoritmo ou programa.
#define Tam 10
int D[Tam];
for (i = 0; i < Tam; i++)
D[i] = Tam – i;
Definir a variável auxilia o programador a não perder a quantidade de elementos do vetor.
int valor=0, E[valor];
pirintf (“Digite o valor do vetor”)
scanf(“%d”, &valor);
for (i = 0; i < valor; i++)
E[ i ] = valor + i;
Com a variável “valor” o usuário tem a possibilidade de definir qual será o tamanho do vetor desejado.
Após a declaração da estrutura dos vetores, é interessante também apresentar o resultado dos elementos inseridos no vetor, para isso é necessário outro comando de repetição para visualizar esses dados.
for (i = 0; i < valor; i++)
printf(“%d Elemento do vetor é: %d”, i, E[ i ])
O vetor é uma ferramenta de grande auxílio quando há a necessidade de armazenamento de várias informações, como datas de aniversário, lista de preços, notas bimestrais dos alunos dentre outras aplicações em que uma variável comum não teria essa capacidade.
Quando um vetor é declarado, é preciso que o programador entenda a organização em que o vetor foi declarado, para poder manipulá-lo de maneira adequada.
int A[5];

O vetor declarado de nome “A” possui 5 elementos em que somente poderá receber valores do tipo inteiro. Tenebaum; Langsam; Augenstein (1995, p.34) afirmam que mesmo com o vetor especificado não quer dizer que a estrutura de dados está totalmente descrita, com isso é preciso especificar como essa estrutura será acessada.
Para acessar o vetor existe a operação de armazenar alguns elementos dentro do vetor. Essa operação pode ser realizada de diversas maneiras. Uma delas é de definir os valores que serão atribuídos ao vetor logo ao declará-lo.
int b[5] = {2, 10, 13, 6, 37};
O vetor “B”, de 5 elementos que recebe cada valor no seu respectivo lugar declarado, a posição “[0]” indica a primeira posição do vetor e a posição “[4]” indica a última posição do vetor, o vetor “B” possui os seguintes valores “2, 10, 13, 6 e 37”.
As operações de armazenamento podem permitir que o usuário insira os elementos que desejar, com a criação de um índice (variável “i”) e utilizando o comando “for” que repete a operação de inserir os dados até que o vetor esteja completo.
int C[10];
for (i = 0; i <= 9; i++)
{
printf (“Insira o valor na posição %d”, i);
scanf(“%d”, &C[ i ]);
}
O comando “for” repete a operação 10 vezes, mostra na tela uma mensagem ao usuário para que insira um valor do tipo inteiro, após as 10 vezes o comando é finalizado. Essa operação tem um bom uso, mas pode melhorar, pois essa repetição corresponde ao tamanho do vetor e em alguns casos o vetor pode ser definido pelo usuário ou pode ter um tamanho pré-definido em que é utilizado para outras partes do algoritmo ou programa.
#define Tam 10
int D[Tam];
for (i = 0; i < Tam; i++)
D[i] = Tam – i;
Definir a variável auxilia o programador a não perder a quantidade de elementos do vetor.
int valor=0, E[valor];
pirintf (“Digite o valor do vetor”)
scanf(“%d”, &valor);
for (i = 0; i < valor; i++)
E[ i ] = valor + i;
Com a variável “valor” o usuário tem a possibilidade de definir qual será o tamanho do vetor desejado.
Após a declaração da estrutura dos vetores, é interessante também apresentar o resultado dos elementos inseridos no vetor, para isso é necessário outro comando de repetição para visualizar esses dados.
for (i = 0; i < valor; i++)
printf(“%d Elemento do vetor é: %d”, i, E[ i ])
O vetor é uma ferramenta de grande auxílio quando há a necessidade de armazenamento de várias informações, como datas de aniversário, lista de preços, notas bimestrais dos alunos dentre outras aplicações em que uma variável comum não teria essa capacidade.
Apresentação do Blog
Olá a todos.
Me chamo Henrique Marangon e sou estudante do 6º Termo do curso de Tecnologia em Informática para a Gestão de Negócios da Fatec Garça.
Esse blog foi criado com o intuito de auxiliar os usuários da Web e os alunos da Fatec a obterem mais conhecimento da Estrutura de Dados. As implementações realizadas no site estarão na linguagem C++ com o intuito de demonstrar a praticidade da programação estruturada e facilitar o aprendizado do usuário.
Agradeço primeiramente a Deus pela oportunidade e idéias que Ele tem dado, ao Profº Maurício Duarte meu orientador que com clareza e objetividade tem me auxiliado no desenvolvimento dos algoritmos, a Profª Maria Alda que nos ajuda na matéria de Graduação, aos professores, aos amigos de sala que lutaram até o final pra concluir o curso, a instituição da Fatec Garça com os equipamentos apropriados para a pesquisa e a você usuário ou aluno que utilizará esse tutorial como uma ferramente nos seus estudos.
Nas postagens a seguir os algoritmos junto com o aprendizado serão colocados no blog.
Me chamo Henrique Marangon e sou estudante do 6º Termo do curso de Tecnologia em Informática para a Gestão de Negócios da Fatec Garça.
Esse blog foi criado com o intuito de auxiliar os usuários da Web e os alunos da Fatec a obterem mais conhecimento da Estrutura de Dados. As implementações realizadas no site estarão na linguagem C++ com o intuito de demonstrar a praticidade da programação estruturada e facilitar o aprendizado do usuário.
Agradeço primeiramente a Deus pela oportunidade e idéias que Ele tem dado, ao Profº Maurício Duarte meu orientador que com clareza e objetividade tem me auxiliado no desenvolvimento dos algoritmos, a Profª Maria Alda que nos ajuda na matéria de Graduação, aos professores, aos amigos de sala que lutaram até o final pra concluir o curso, a instituição da Fatec Garça com os equipamentos apropriados para a pesquisa e a você usuário ou aluno que utilizará esse tutorial como uma ferramente nos seus estudos.
Nas postagens a seguir os algoritmos junto com o aprendizado serão colocados no blog.
Assinar:
Postagens (Atom)
